Educational Cards
Learn from video content, text, and interactive tasks
Filters

Row picture: rows of $A$ dot columns of $B$
Entry (i,j) of AB is row i of A dotted with column j of B. Useful when interpreting rows as...
Powers and repeated transformations
Applying the same map k times corresponds to A^k when well-defined. Diagonalization later makes...

Lead-in: eigenbasis is the ultimate friendly coordinate change
When enough eigenvectors span the space, a matrix B built from them diagonalizes M = B D B^-1 with...
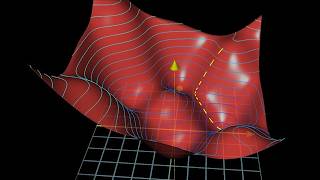
Learning rate as step size: fragile knob
The learning rate eta controls how far each descent step moves in weight space. Too small and...
Local minima, saddles, and plateaus
Zero gradient marks a critical point , but not every critical point is a desirable resting place. A...

Structured graphs: weight sharing and modular layers
Production networks are not bare MLP chains. Convolutions reuse the same kernel at every spatial...
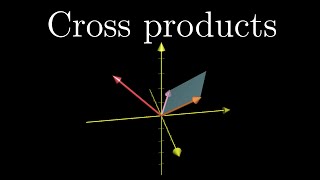
Torque and angular momentum hooks
Mechanics uses boldsymboltau=mathbfrtimesmathbfF because only the perpendicular lever arm...

Adjugate / cofactor matrix viewpoint (conceptual)
The adjugate (classical adjugate) records how normals and oriented 2-faces transform under a linear...

Invertibility test: $\det A\neq0$ for square matrices
For square A, det Aneq 0 is equivalent to invertibility on finite-dimensional spaces: trivial...

Linear independence: no hidden redundancy in the generator list
Vectors are linearly independent when the only combination giving mathbf0 is the trivial one with...

Log-space and stabilization patterns
Softmax exponentials can overflow when logits are large and underflow when logits are very...
Higher-order vs first-order in deep learning
SGD and Adam use first derivatives only. Newton methods incorporate curvature via the Hessian,...