Log-space and stabilization patterns
Softmax exponentials can overflow when logits are large and underflow when logits are very negative. The standard fix subtracts $m = \max_i z_i$ before exponentiating:
$$\mathrm{softmax}(z)_k = \frac{e^{z_k - m}}{\sum_j e^{z_j - m}}.$$
Probabilities are unchanged because numerator and denominator share the same factor $e^{-m}$, but numeric range improves .
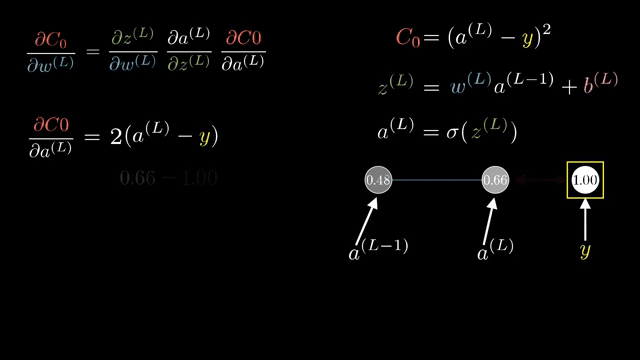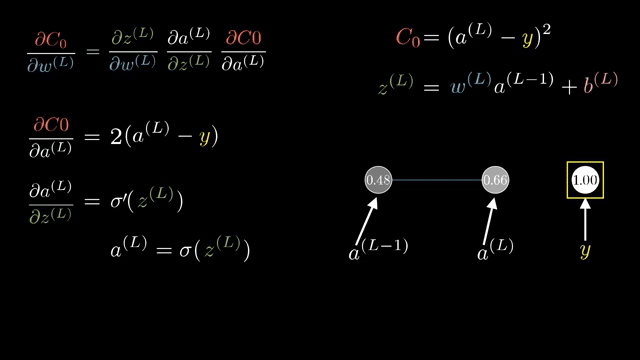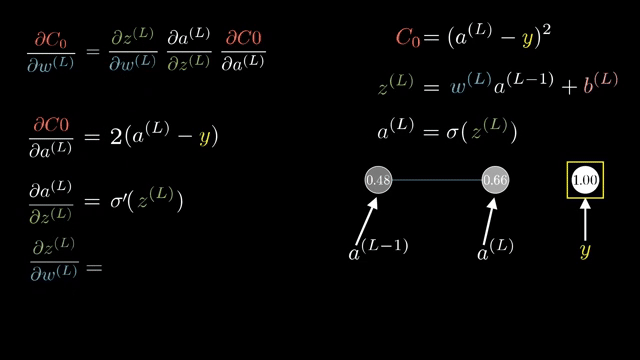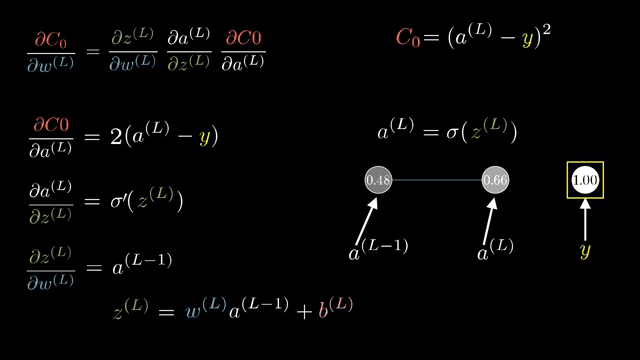
Log-sum-exp aggregates logits in log space: $\mathrm{LSE}(z) = \log\sum_j e^{z_j}$, again with the max trick for stability. Fused log-softmax kernels avoid computing probabilities explicitly, reducing underflow in downstream log terms .
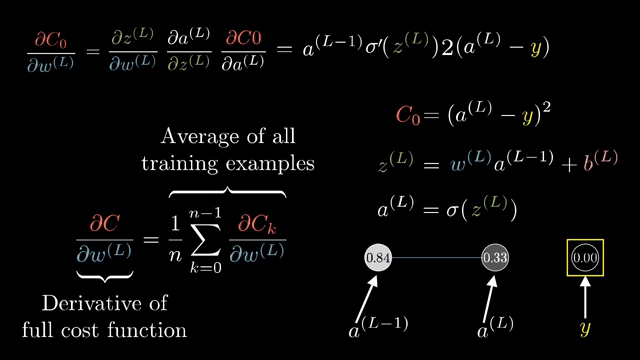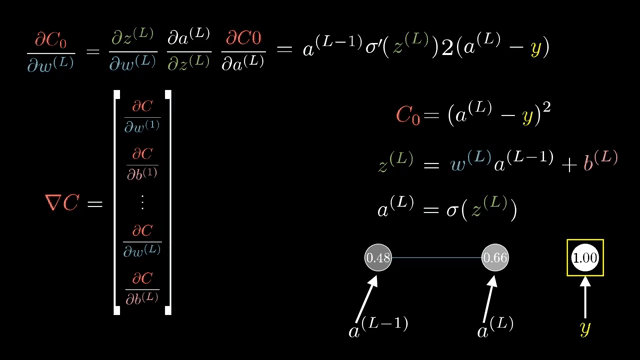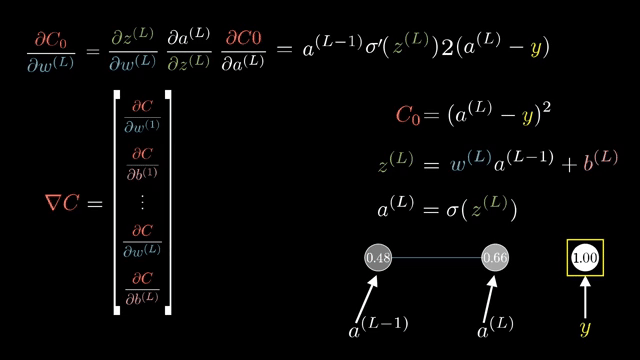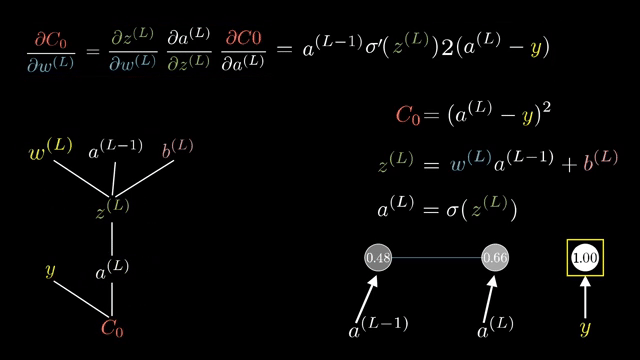
Even with stable kernels, logits that are extremely positive for wrong classes can yield nearly one-hot softmax outputs and tiny gradients on the correct class. Label smoothing spreads a small amount of target mass onto non-true classes to reduce overconfidence .
Understanding these patterns explains occasional NaNs in naive user code even when the mathematics is correct on paper .
Cross-entropy loss $\ell = -\log p_y$ combined with log-softmax output $\log p_i$ is often implemented as a single fused op whose backward returns $\partial \ell/\partial z_i = p_i - \mathbb{1}_{i=y}$ in the standard setup, a formula worth memorizing after you derive it once by hand .
Watch for $\log(0)$ when probabilities underflow: even stable softmax can produce gradients that are finite yet enormous if learning rates are not tempered during early training .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
