Structured graphs: weight sharing and modular layers
Production networks are not bare MLP chains. Convolutions reuse the same kernel at every spatial location; batch normalization couples batch statistics to each activation; attention mixes tokens through softmax weights. Each block is still a DAG node with registered forward and backward rules, often fused into single GPU kernels .
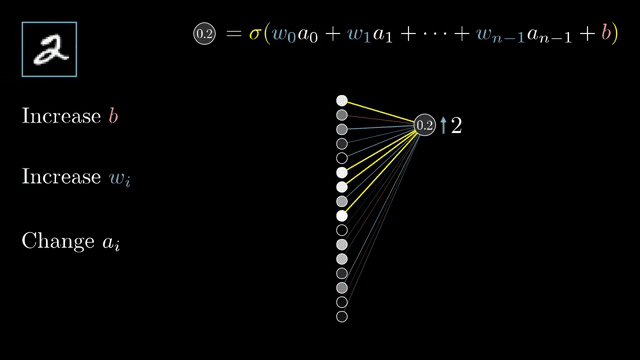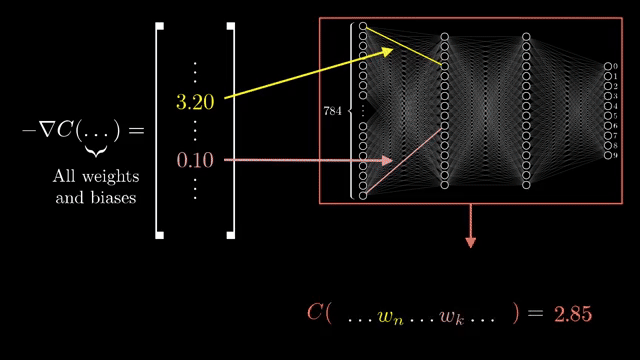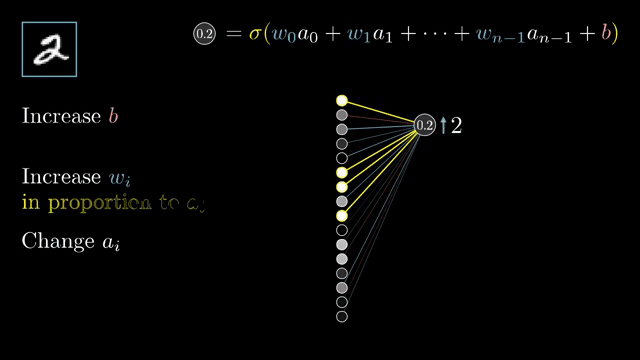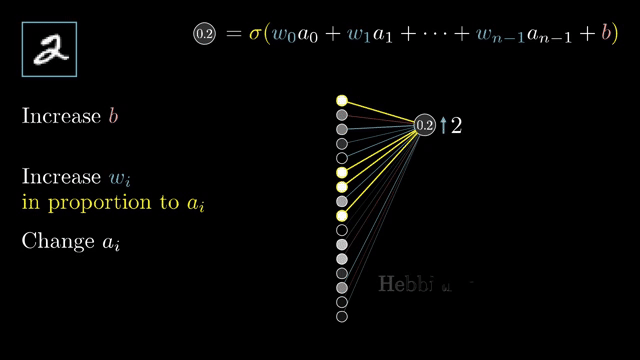
Weight tying means one parameter tensor feeds multiple operations. Gradients w.r.t. that tensor sum contributions from every use site, exactly like fan-out summation in the chain rule .
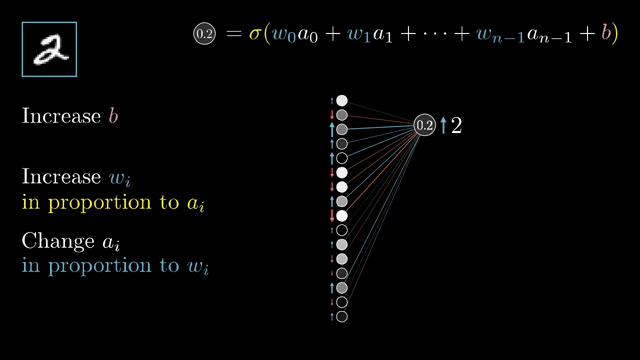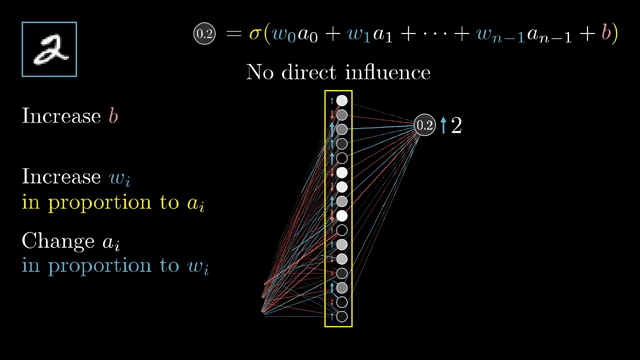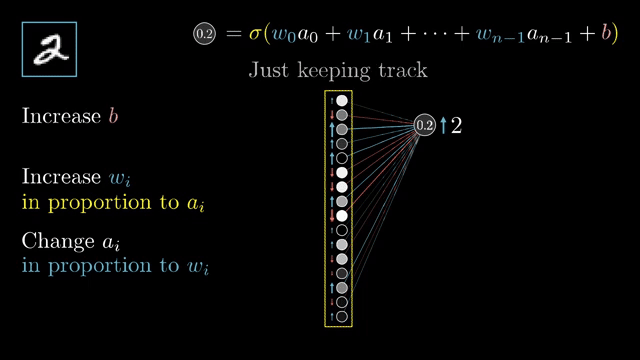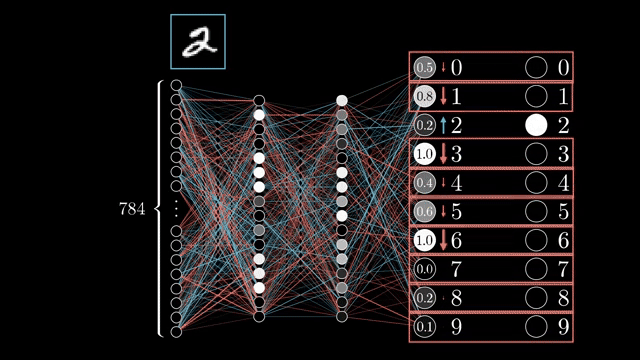
Softmax is a coupling example: each output probability depends on all logits, so its Jacobian is generally dense, not diagonal. That is why naive softmax followed by log can underflow, while fused log_softmax plus negative log-likelihood loss keeps computations in log space .
In-place tensor operations can silently break autograd if they overwrite values still needed for backward. Custom layers must register correct backward kernels or training will diverge in subtle ways .
Batch normalization backward depends on batch statistics computed during the forward pass; eval mode freezes running averages instead. Each such layer is another node whose local Jacobian structure must be coded correctly .
Convolution backward is not magic: it is the same fan-out summation, but the shared kernel means many edges reuse identical weight indices, so gradients to that kernel accumulate from every spatial position .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
