Forward-mode vs reverse-mode: when each wins
Automatic differentiation has two standard modes. Forward mode seeds a perturbation on one input direction and propagates its influence through every output: cheap when inputs are few and outputs are many. Reverse mode seeds sensitivity on one scalar output and propagates backward to all inputs: cheap when outputs are one loss and inputs are millions of weights .
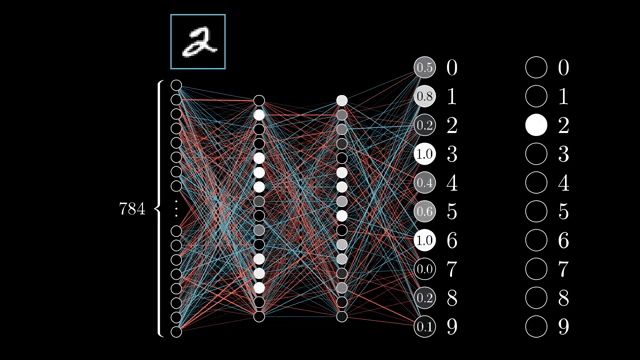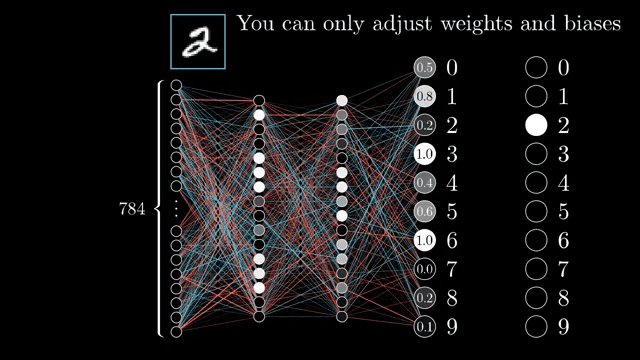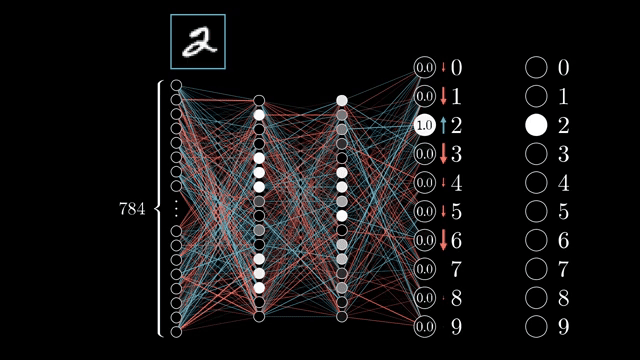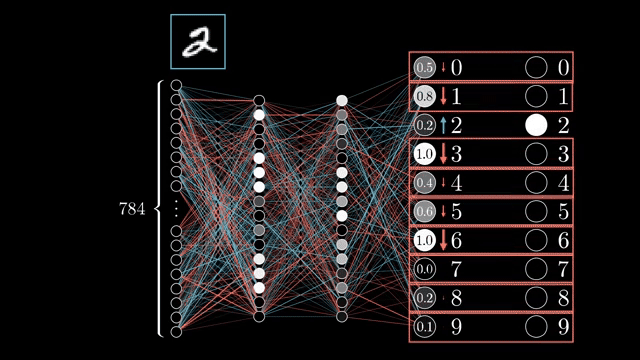
Neural network training is the canonical reverse-mode case: one cross-entropy scalar, huge parameter vector. Forward mode would require one pass per parameter to build a full Jacobian column, which is untenable .
Full Jacobians for wide layers can be $4096\times 4096$ or larger; frameworks never materialize them. Instead they expose Jacobian-vector products (JVPs) and vector-Jacobian products (VJPs) as primitive operations .
Pearlmutter-style tricks compute Hessian-vector products with two AD passes without forming the Hessian explicitly, enabling curvature probes for research optimizers while staying tractable at moderate width .
If you ever implement a custom loss that returns a vector of per-example costs, remember that reverse mode expects a scalar seed unless you sum or weight those outputs explicitly before calling backward .
Jacobian columns answer sensitivity to one input coordinate; Jacobian rows answer sensitivity of one output coordinate. Training cares about the row picture aggregated through the scalar loss .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
