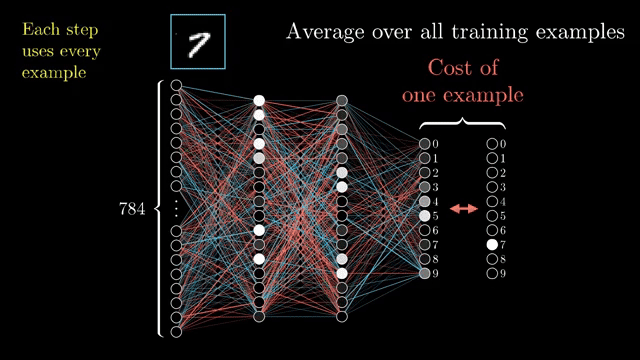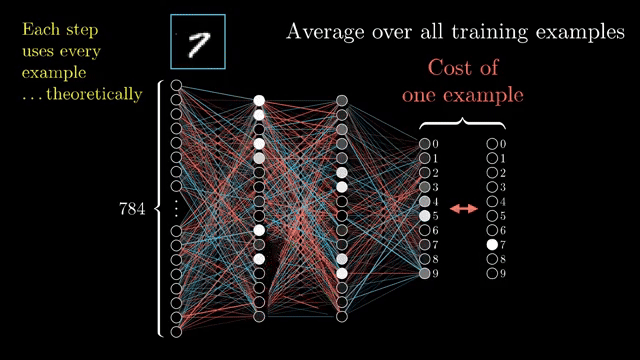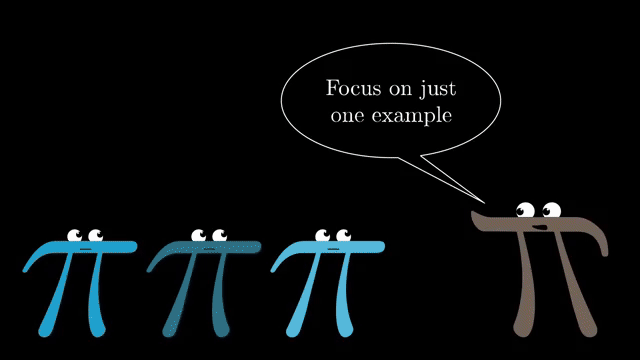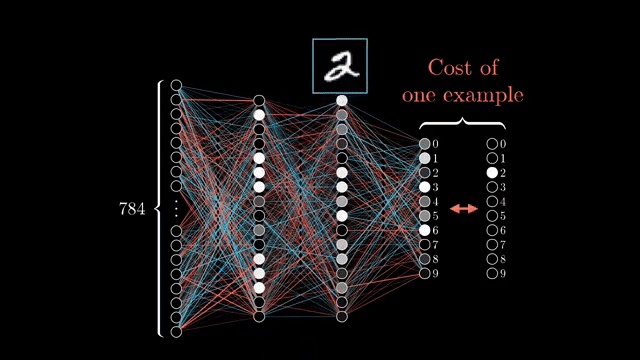
Memoization: forward activations feed backward formulas
Automatic differentiation frameworks tape the forward computation: each op records inputs and enough metadata to run its backward rule. A ReLU backward needs to know which preactivations were positive; softmax backward needs logits and the normalized probabilities; max-pooling backward needs argmax routes that record which input won each window .
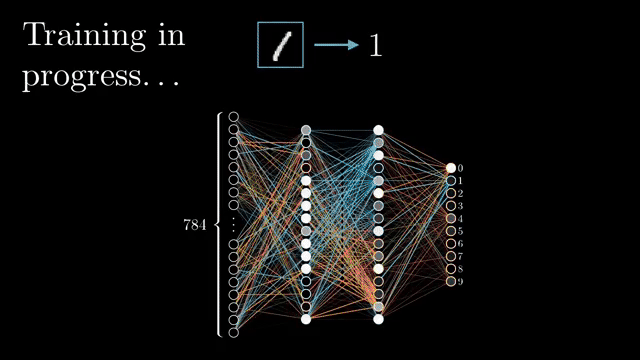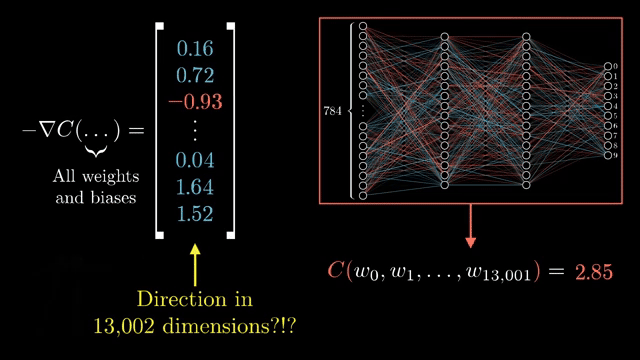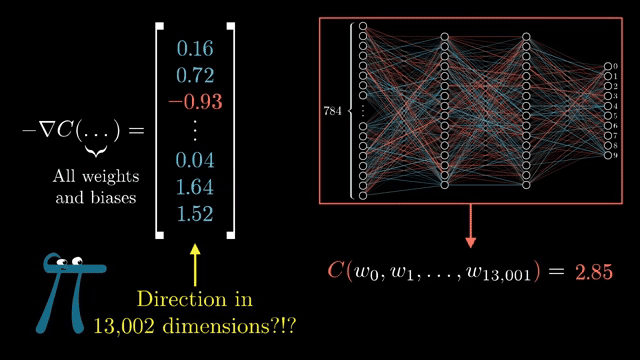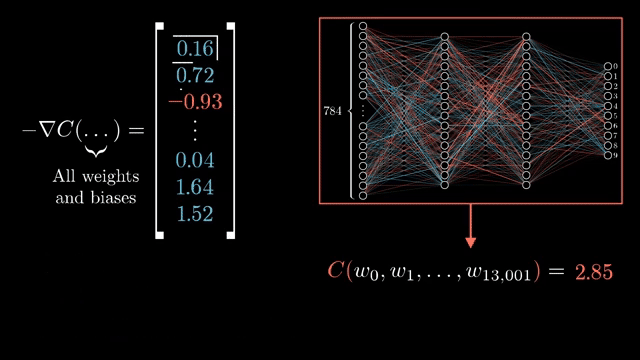
This memoization is not free. Storing every intermediate for a deep network can exhaust GPU memory. Gradient checkpointing trades compute for memory: some activations are discarded and recomputed during the backward pass when their local formulas need them .
Framework APIs let you detach tensors to cut gradient flow through an edge, useful for frozen layers or reinforcement-learning baselines. Higher-order gradients require differentiating through the backward implementation itself, which doubles memory pressure and is far less common in standard training .
At minimum, each graph node must know how to compute its output from parents and how to implement the local vector-Jacobian product that maps an upstream gradient into gradients w.r.t. inputs .
During training, memory planners must budget for both weights and saved activations. That is why inference-only deployment can use less memory than training the same architecture at the same batch size .
ReLU backward is especially simple: the mask of positive preactivations multiplies the upstream gradient elementwise. Sigmoid backward instead multiplies by $\sigma'(z)$, which shrinks when activations saturate .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
