MNIST-style digits as a running example
The running example is handwritten digit recognition on $28\times 28$ grayscale images, 784 pixels flattened into the input vector. Humans read sloppy threes at low resolution effortlessly; programming explicit rules for every stroke variant is the hard task the network is meant to learn .

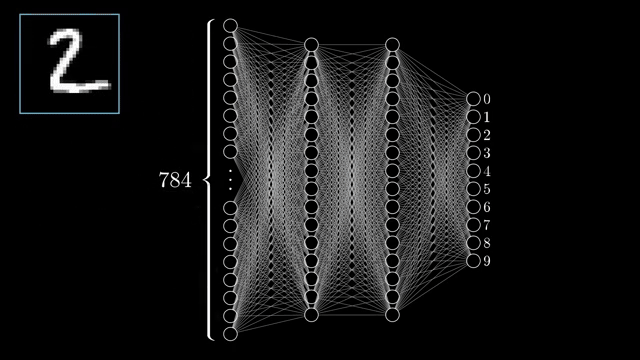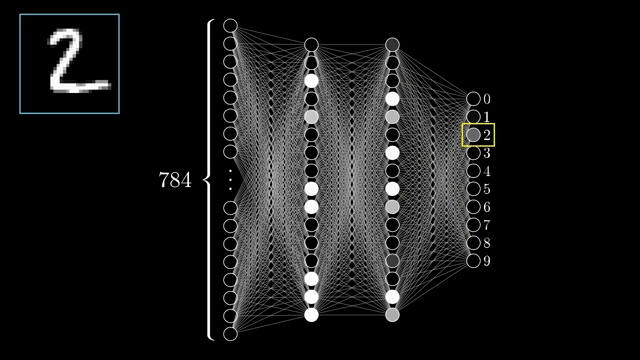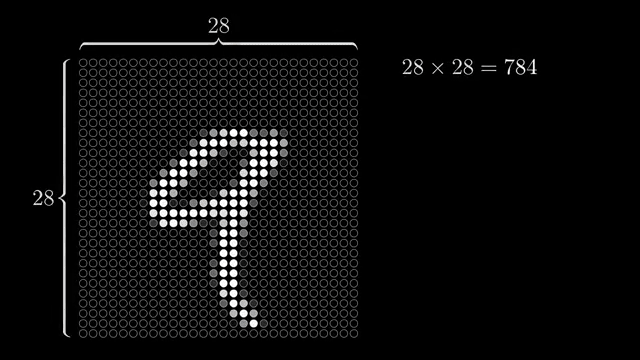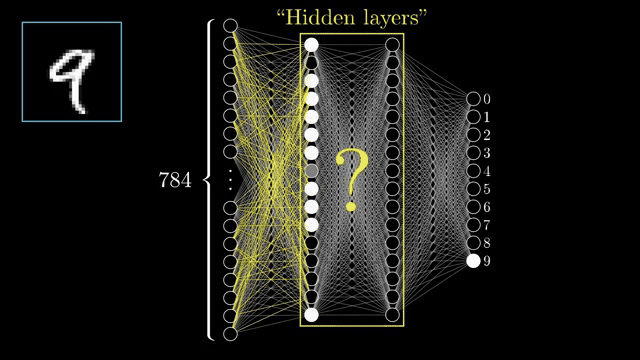
Each input neuron stores one pixel brightness in $[0,1]$ (0 black, 1 white). Those 784 numbers are the first layer. The output layer holds 10 neurons, one per digit class. After a forward pass, the brightest output activation is the network's guess .

Between input and output sit hidden layers, latent representations not directly observed from pixels or final labels during inference. The chapter uses two hidden layers of 16 neurons each; that width is a screen-friendly choice, not a universal law .
Training (next chapter) compares predictions with one-hot targets and drives down cross-entropy loss against a softmax output distribution. Inference reuses the learned weights: only forward propagation, no gradient pass. MNIST is a clean sandbox, centered digits, fixed size, while real vision adds clutter, viewpoint, occlusion, color, fine-grained categories, label noise, and domain shift .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Beginner
- Completed: 0 users
Creator
