Why depth needs nonlinear breaks
Before the algebra, the narrative asks for a hope about hidden layers: maybe a penultimate layer detects human-interpretable parts (loops, stems, long vertical strokes), and the final layer mixes those parts into digit decisions. A 9 shares a top loop with an 8; a 4 breaks into line segments; recognizing a loop itself decomposes into edge detectors .
That story only works if intermediate features can be recombined nonlinearly. If every layer were a plain matrix multiply, stacking depth would still be one affine transformation of the input; extra layers would not add new kinds of folding in representation space. Inserting sigmoid, tanh, ReLU, or similar gates lets later layers build on curved features instead of a single flat mix .
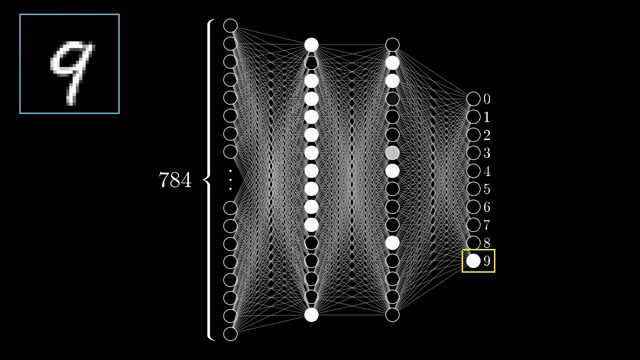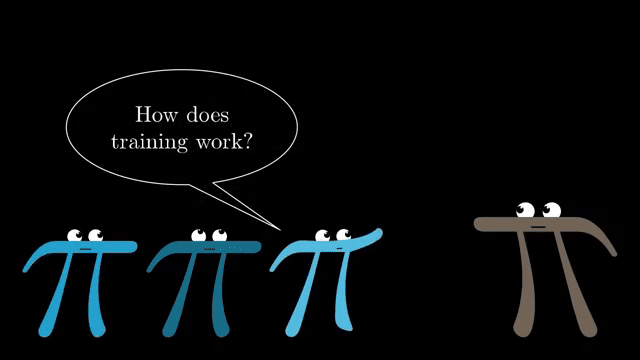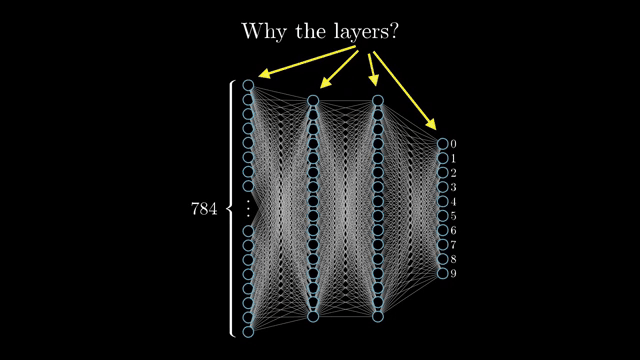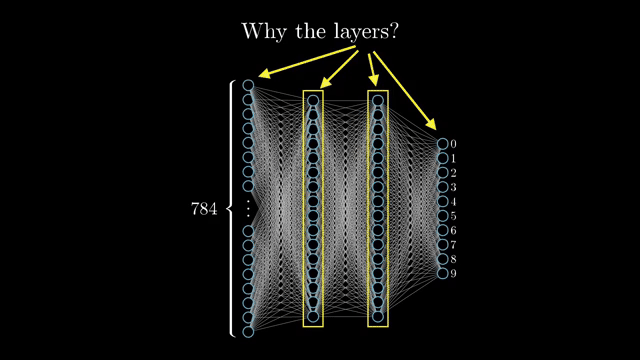
Width also matters: a shallow network with enough hidden units can approximate many functions in principle, yet deep stacks often reuse intermediate abstractions so the same edge detectors serve many downstream patterns. That is an efficiency story, not a claim that shallow nets are useless .

At the output, class scores are often written as logits, real numbers before any normalization. Softmax (covered next) turns logits into probabilities; during this chapter's visualization, output activations are already squashed into $(0,1)$, but the pedagogical point remains: the network emits comparative evidence per class, not arbitrary unrelated labels. ReLU activations $\max(0,x)$ became the modern default partly because they avoid the flat saturated regions of sigmoid/tanh that shrink gradients in very deep stacks .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Beginner
- Completed: 0 users
Creator
