Parameter counting and width vs depth intuition
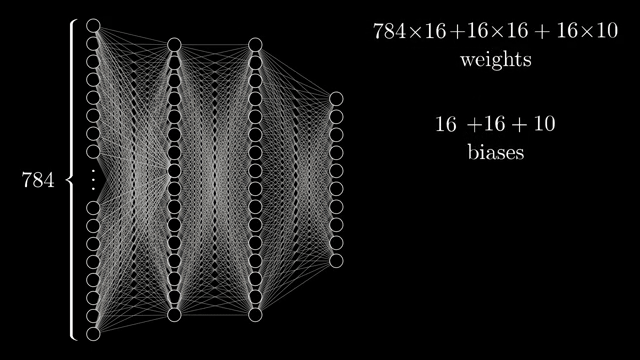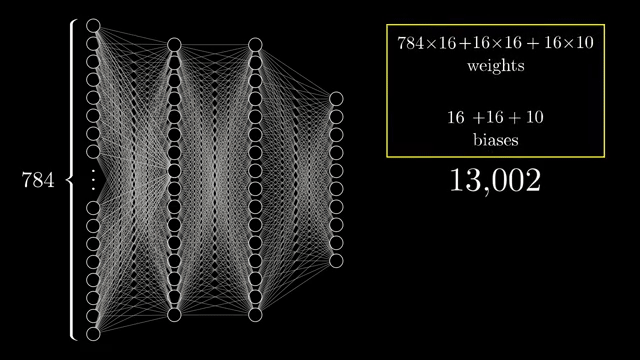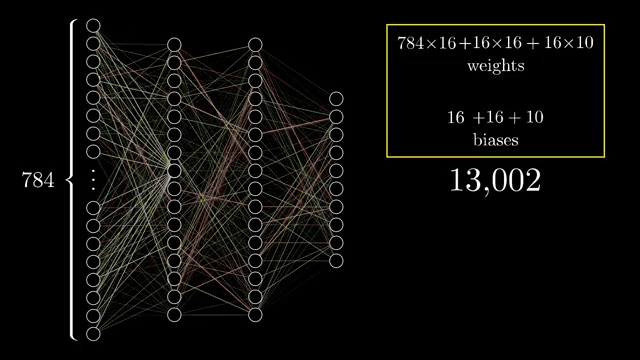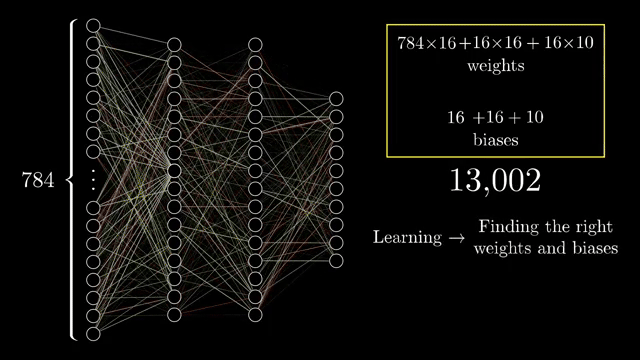
Every weight and bias is a learnable knob. The demo network connects all 784 inputs to each of 16 neurons in the first hidden layer. That alone is $784\times 16$ weights plus 16 biases, and similar matrices sit between subsequent layers .
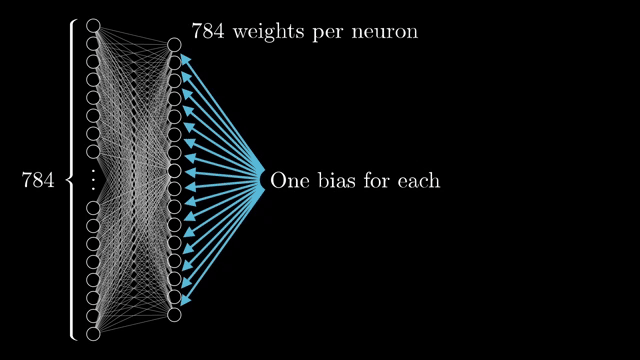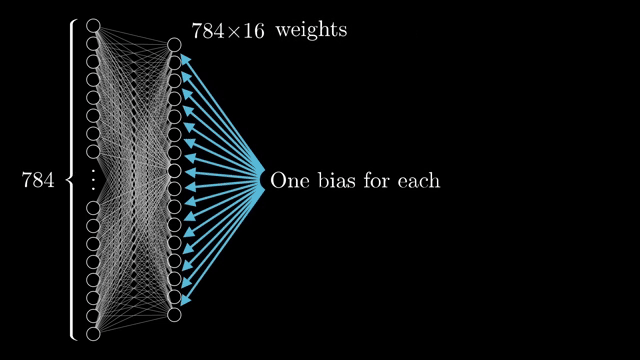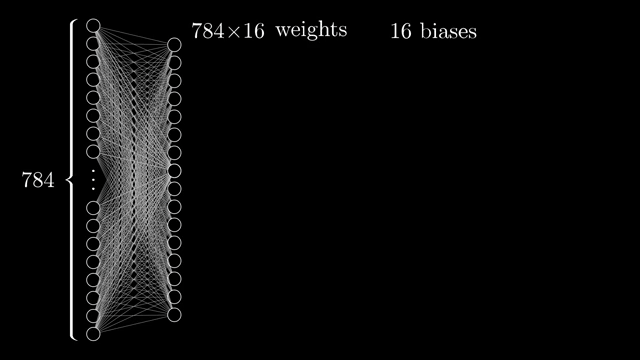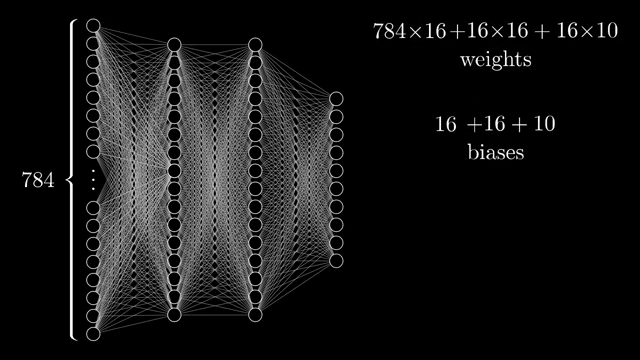
Counting everything, the chapter network has on the order of 13{,}000 parameters. Learning means searching for a setting of those numbers that reduces average classification error on examples, a staggering hand-tuning problem if you imagine assigning each dial manually .
Fully connecting every pixel to a wide hidden layer scales poorly as resolution grows; convolutional architectures (later courses) share weights across spatial positions to exploit locality and translation structure. A single-layer perceptron without hidden units implements a linear decision boundary in raw pixel space, only linearly separable problems are easy there .
Depth helps composition: early layers can build edges, later layers assemble them into parts, and the head combines parts into classes. The same parameter budget spread across layers can represent hierarchical features rather than one monolithic mixing step, the layered story is about reusable parts, not one giant lookup table .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Beginner
- Completed: 0 users
Creator
