Retrieval-augmented generation and tool use
Parametric weights cannot stay current with the live web. Retrieval-augmented generation (RAG) conditions the model on retrieved passages inserted into the prompt context window . Dual-encoder contrastive training aligns queries and documents in a shared embedding space for efficient search .
Enterprise RAG stacks add rerankers, access-control filters on document IDs, and logging of retrieved chunks for audit. Without logging, debugging a wrong answer means guessing which passage misled the model .
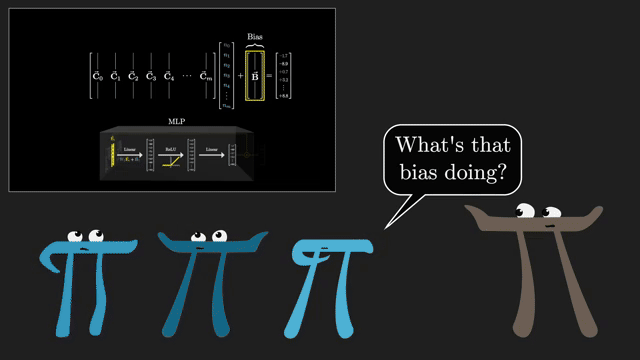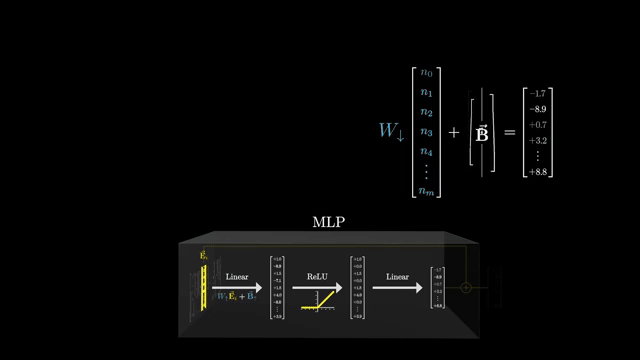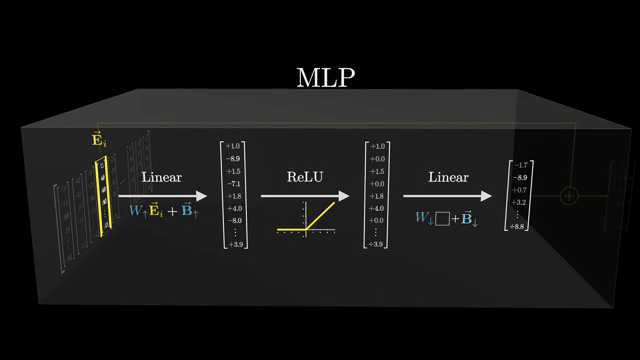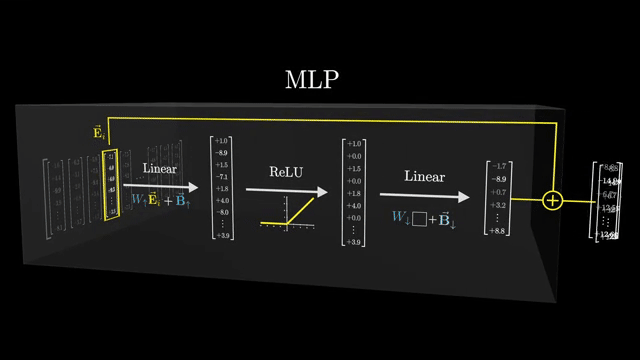
Toolformer-style training encourages models to emit API calls (calculator, search, database) when external computation beats parametric guessing . Retrieval quality, citation honesty, and stale corpora remain bottlenecks: wrong documents produce confident wrong answers .
Adversarially poisoned retrieval can steer outputs toward malicious content. RAG shifts failure modes from pure hallucination to grounded hallucination when citations lie .
RAG pipelines need freshness metadata so the model can reason about recency. Citations should map to retrievable IDs; otherwise the model invents plausible references that pass casual inspection .
Tool APIs should return structured JSON the model can quote; free-form tool text increases injection risk and makes citation auditing harder .
Hybrid answers should separate quoted evidence from model synthesis so users can verify claims without trusting fluent prose alone .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Advanced
- Completed: 0 users
Creator
