Sparse autoencoders and feature directions
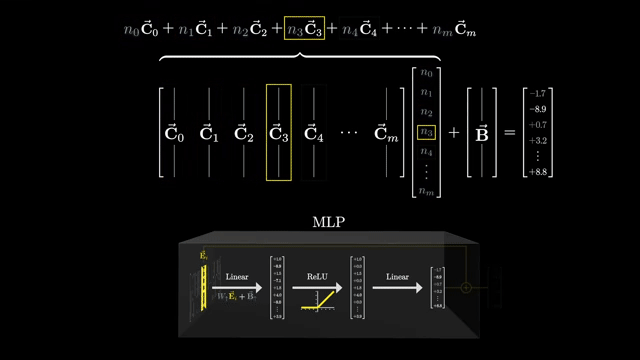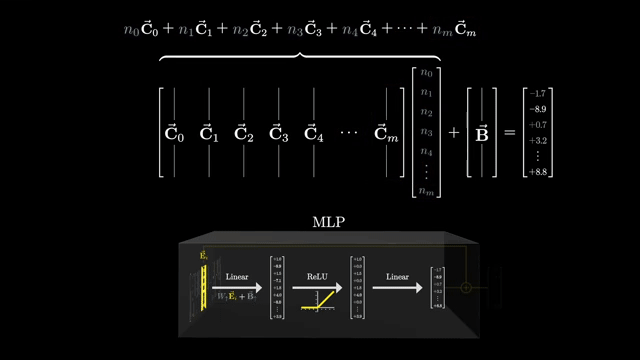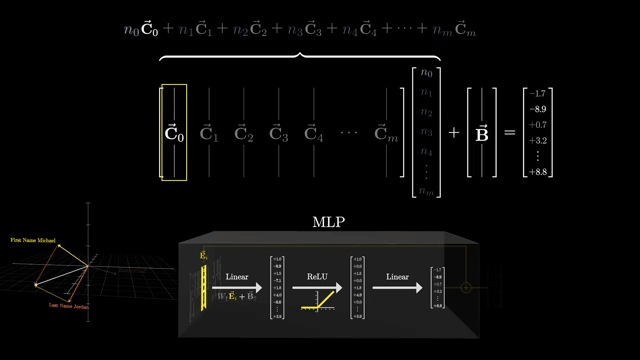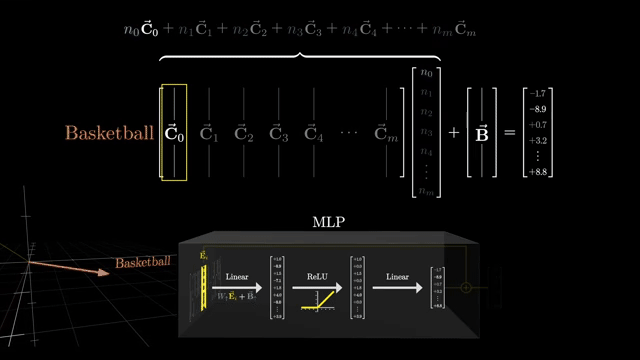
Sparse autoencoders (SAEs) train on internal activations to reconstruct them from a larger sparse latent code. The hope: dictionary elements align with interpretable feature directions rather than polysemantic mush .
Each example activates only a few latent units (sparsity), making attribution easier than reading dense superposition directly. Reconstruction error trades off against sparsity penalty strength: too sparse and you lose information; too dense and features stay entangled .
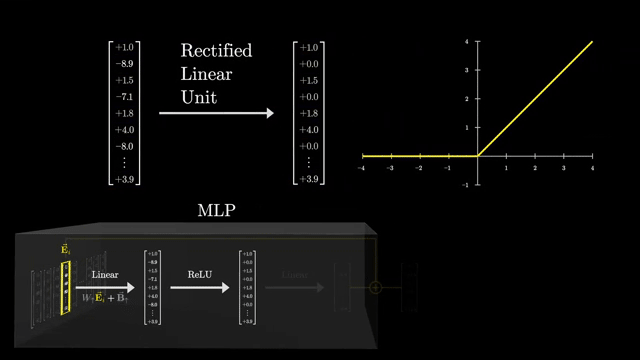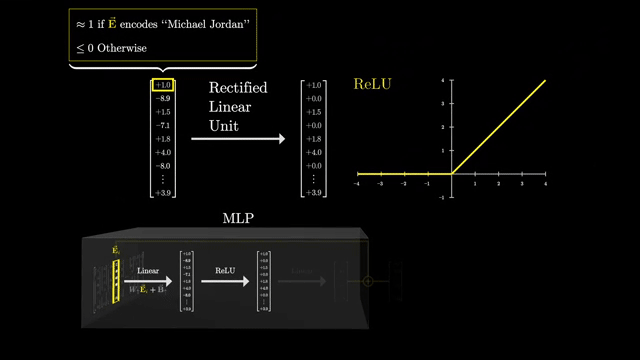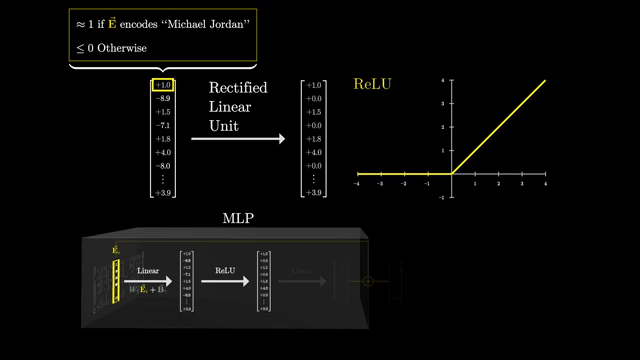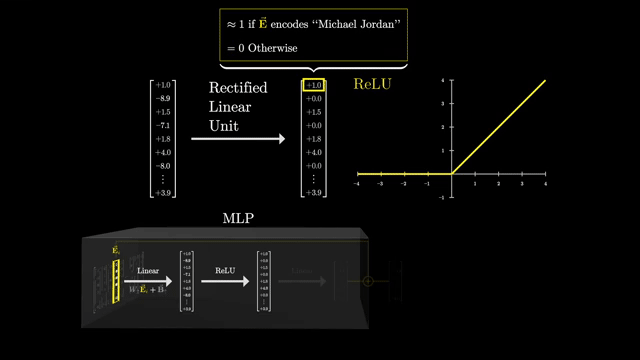
Dictionary learning analogies are apt: activations are approximated as sparse combinations of basis directions in activation space. SAEs are research-grade tools, not a complete safety solution .
They reveal partial structure on activations but do not guarantee robust behavior under adversarial prompts or distribution shift .
SAE training requires careful choice of layer and token position: mid-residual features differ from post-MLP activations. Researchers compare reconstruction quality to human concept lists, not deployment safety guarantees .
Increasing sparsity penalty too aggressively yields dead latents that never fire; monitor active latents per token when tuning SAEs .
Open-source SAE releases on mid-layer residuals invite replication: compare sparse feature dashboards across prompts before claiming a feature is universal .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Advanced
- Completed: 0 users
Creator
