Catastrophic forgetting and continual learning pain
Fine-tuning updates weights to fit new data. Those same weights encoded prior abilities; catastrophic forgetting is the sharp drop in performance on old tasks after new-task training .
The plasticity-stability tradeoff has no free lunch: more adaptation to new data means more drift from the old optimum. Replay mixes old examples into new training; elastic weight consolidation penalizes changes to parameters deemed important for prior tasks .
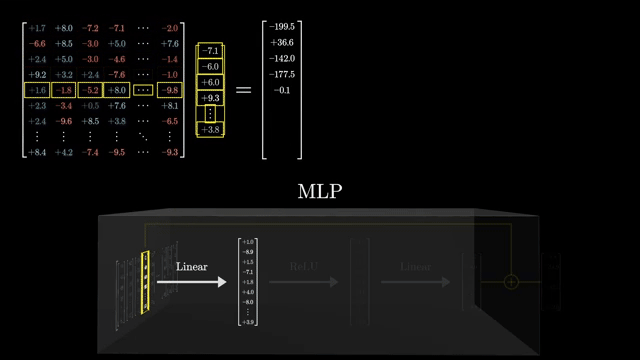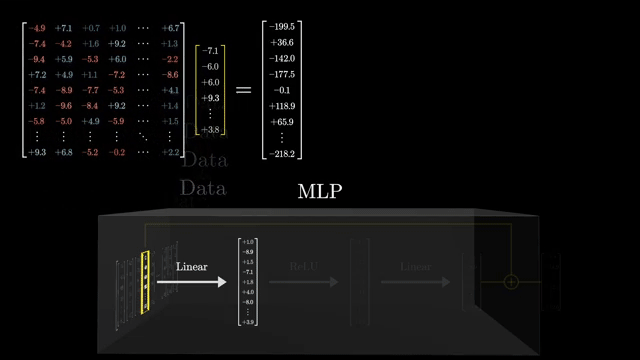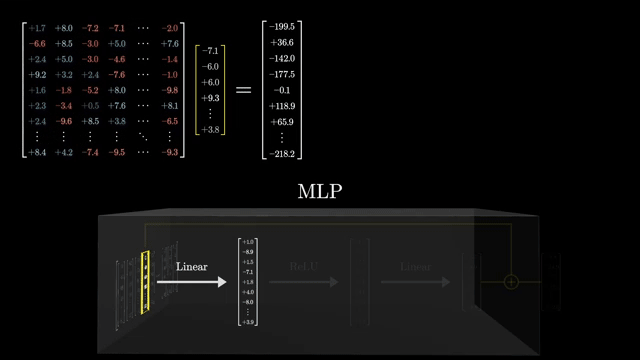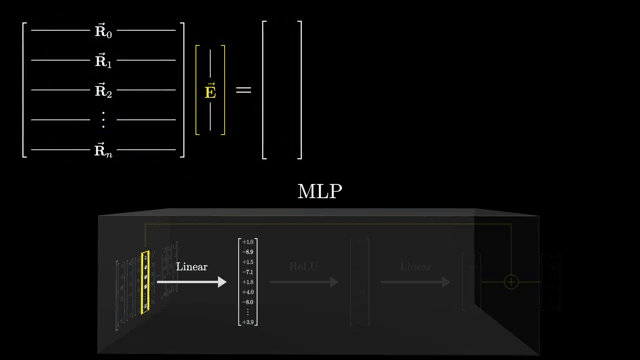
LoRA (low-rank adaptation) injects trainable rank-$r$ factors while freezing most base weights: $W' = W + BA$ with small $B, A$. Enterprises can version a frozen base model and iterate task-specific adapters for rollback and audit .

Continual learning remains an open research area; production systems often prefer retrieval and tooling over endless parametric updates .
Enterprise pipelines often freeze a base checkpoint, version adapters per customer, and run regression suites on legacy tasks before promotion. Forgetting appears as silent quality drift rather than one loss spike .
Replay buffers store a fraction of old task data during continual learning; the buffer size becomes a privacy and storage policy decision, not only an algorithmic knob .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Advanced
- Completed: 0 users
Creator
