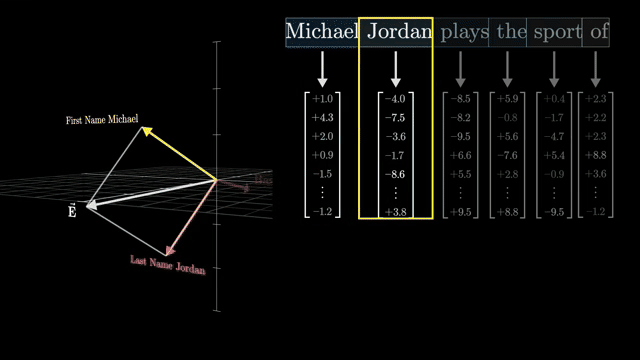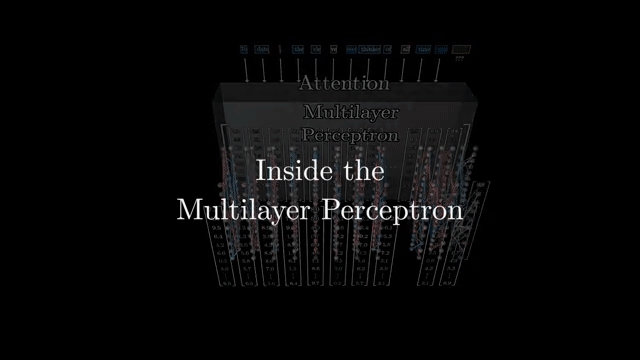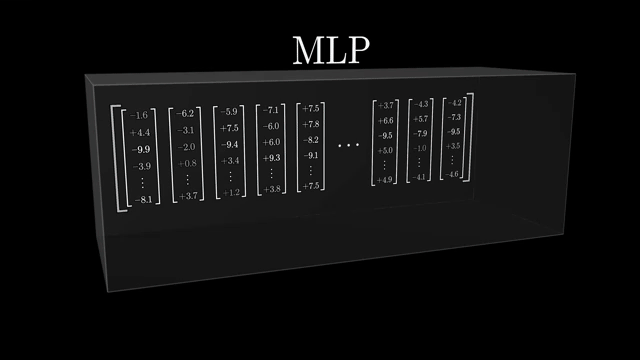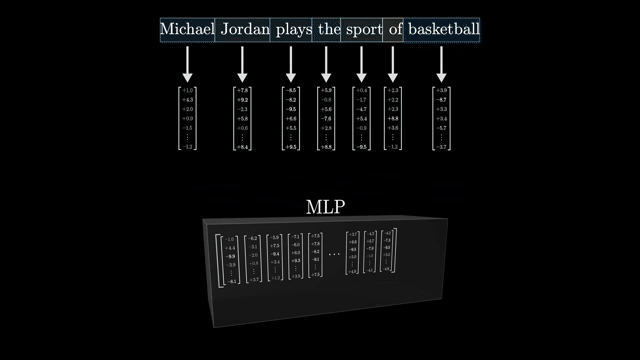
MLP neurons as key-value-ish nonlinear transforms
Transformer MLP blocks widen activations, apply a smooth gate (GeLU, SiLU), then project back to model width. The exposition draws a loose analogy to key-value memory: up-projection expands into a higher-dimensional space where nonlinear gates select features; down-projection compresses back .
Typical expansion ratio is $4\times$: if $d_{\text{model}} = 4096$, the intermediate layer may be 16384 wide before the second linear map shrinks back. SwiGLU variants gate one projection with a swish-activated branch, common in PaLM and LLaMA families .
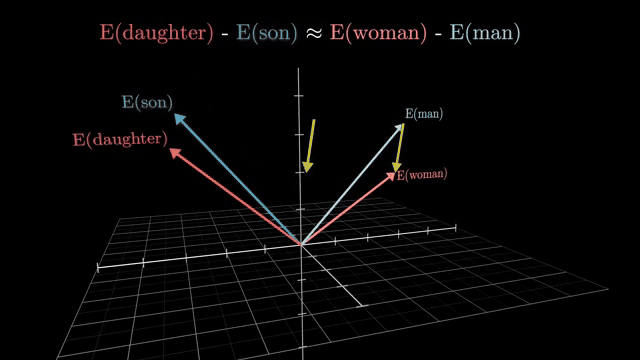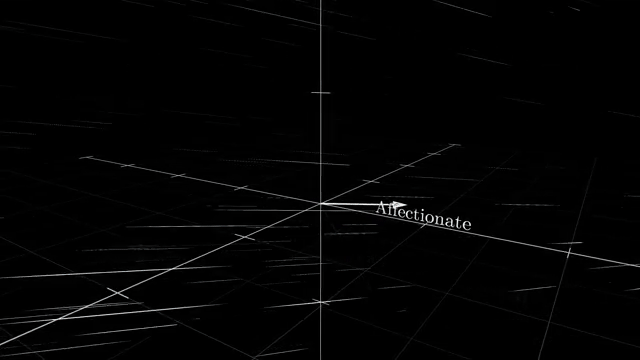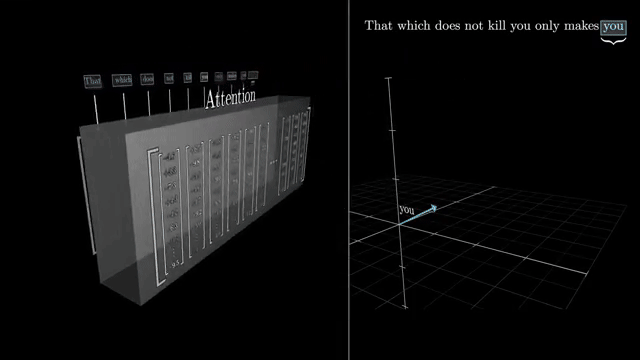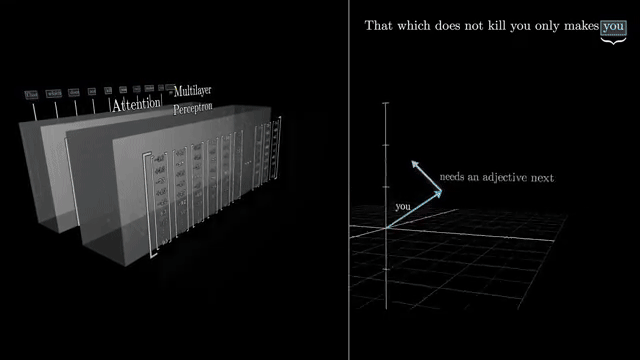
The bottleneck structure enforces a low-rank pass through the nonlinear gate: intermediate features live in a compressed subspace before re-expansion. That limits representational width at the gate but keeps parameter count manageable .
GeLU and SiLU differ from ReLU in curvature near zero; smooth gates change gradient flow during training compared with hard zeroing .
Unlike a database, MLP weights are trained jointly with attention and updated by every gradient step. Editing one fact can ripple through overlapping features stored in superposition .
PaLM and LLaMA families increased FFN ratio and switched to gated activations; when comparing memory analogies across architectures, match expansion ratio and activation choice .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Advanced
- Completed: 0 users
Creator
