Parametric memory is distributed, not a tidy file cabinet
When a model answers "Paris is the capital of France," where did that fact live? Not in a single addressable row. Parametric memory spreads associations across millions of weights; factual recall emerges from high-dimensional interference patterns and context-dependent activations .
Mechanistic interpretability tries to reverse-engineer circuits: subgraphs of attention heads and MLP neurons that implement recognizable operations. Progress is real but partial; most internal structure remains opaque .

Polysemantic neurons fire on multiple unrelated features in superposition: one unit might respond to both a syntactic pattern and a factual association. Knockout and ablation experiments perturb activations to test causal influence on outputs .
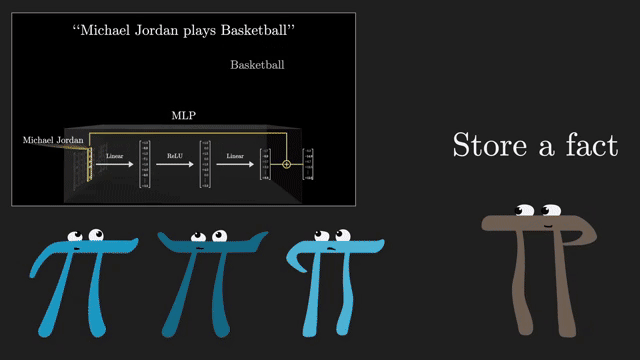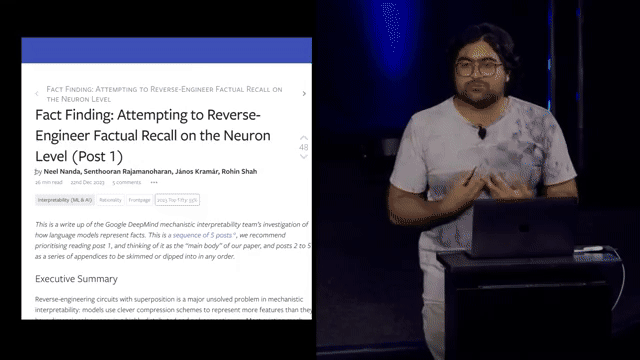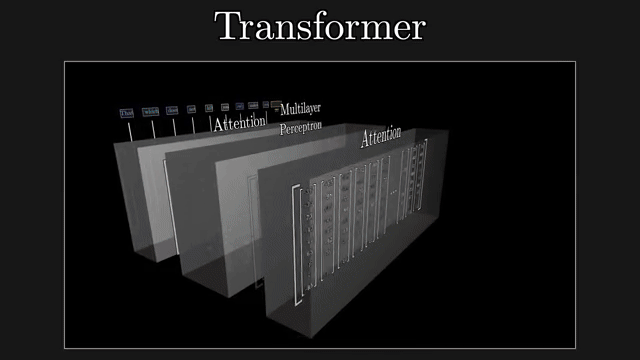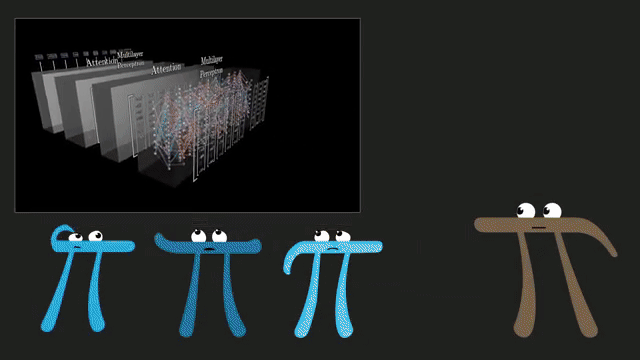
Claiming "neuron 1737 stores the capital of France" without caveats is misleading. Features are distributed, context-dependent, and may shift under prompt or domain change .
Interpretability progress is uneven across layers: early layers track local syntax while mid-layer MLPs correlate with factual recall in some probes. None of this yields a complete map; it motivates experiments rather than confident neuron labels .
Probing classifiers on activations can predict attributes without revealing a simple internal lookup table; high probe accuracy still does not imply a clean causal circuit usable for editing .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Advanced
- Completed: 0 users
Creator
