Higher-order vs first-order in deep learning
SGD and Adam use first derivatives only. Newton methods incorporate curvature via the Hessian, giving better local step directions but costing far more per iteration. At LLM scale, exact second-order steps are impractical except in tiny subspaces .
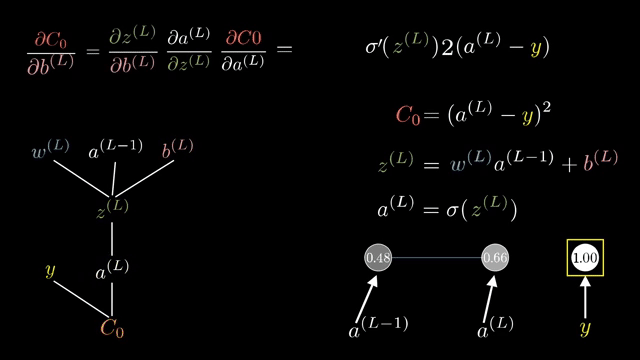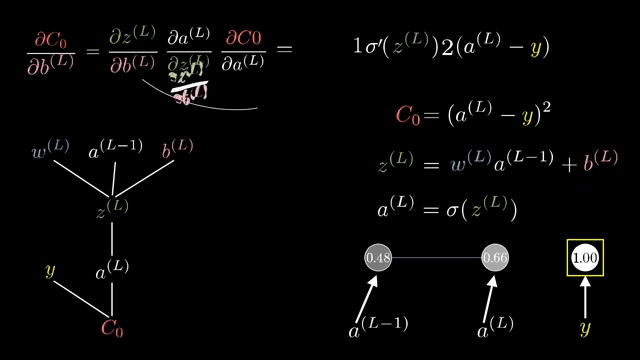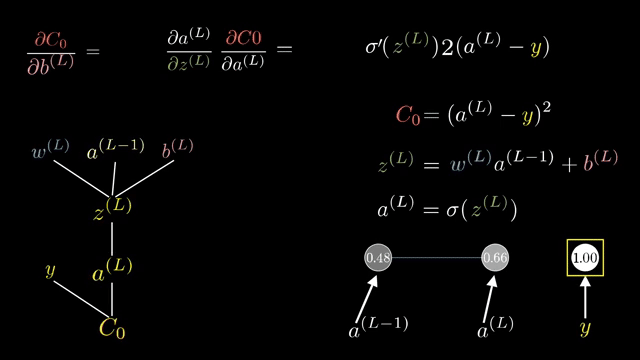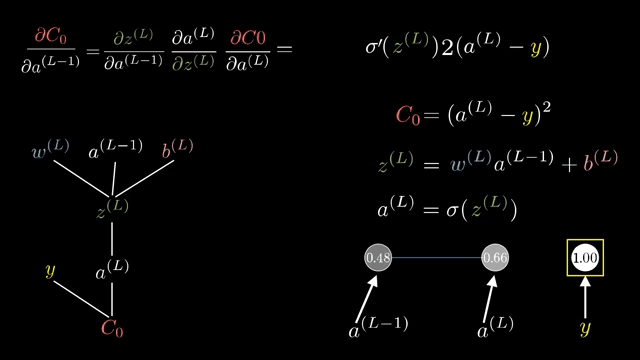
The Gauss-Newton approximation exploits least-squares structure, dropping certain second-derivative terms involving residuals. L-BFGS stores low-rank secant information to approximate inverse curvature without forming full matrices .
Research approximations like K-FAC factor curvature blockwise; most transformer training still relies on AdamW, warmup, clipping, and mixed precision rather than exact Newton steps .
Second-order methods remain rare at frontier scale because Hessian memory and per-step linear algebra dominate budgets unless heavily approximated .
First-order methods tolerate noise from minibatches and approximate Hessians poorly anyway at scale, which partly explains why AdamW plus careful engineering dominates transformer pretraining pipelines .
Newton steps also require solving linear systems involving curvature; that cost dwarfs a single gradient pass when parameter counts reach billions, before you even discuss noisy minibatch estimates of Hessians .
When you do use curvature, it is usually through diagonal or block-diagonal approximations that ignore cross-parameter coupling, another reminder that exact second-order methods are ideals rather than defaults .
Treat second-order intuition as a lens on loss geometry, not a recipe you must implement to train MNIST .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
