JVPs and VJPs without_full Jacobians
A full Jacobian for a layer mapping $\mathbb{R}^{4096}\to\mathbb{R}^{4096}$ has roughly sixteen million entries. Frameworks never store it. Instead they implement Jacobian-vector products (JVPs): apply $J$ to a tangent vector without forming $J$. Vector-Jacobian products (VJPs) apply $J^T$ to an upstream gradient; backprop is built from VJPs .
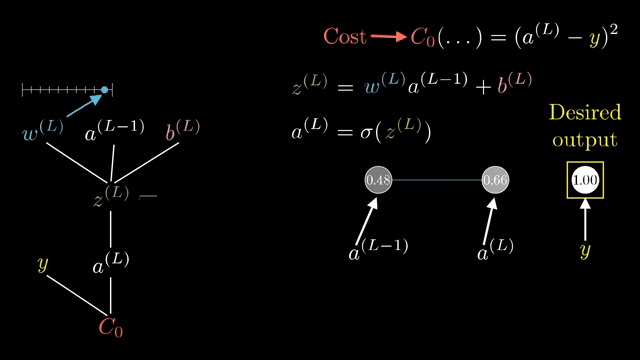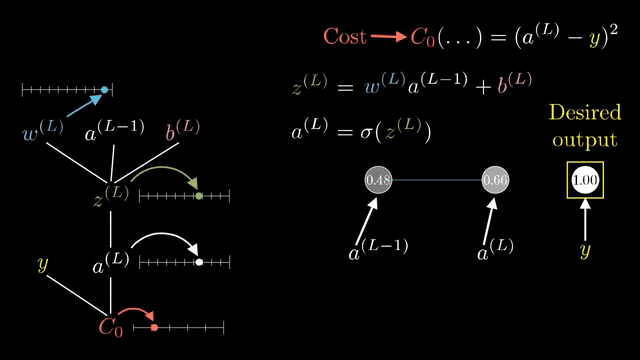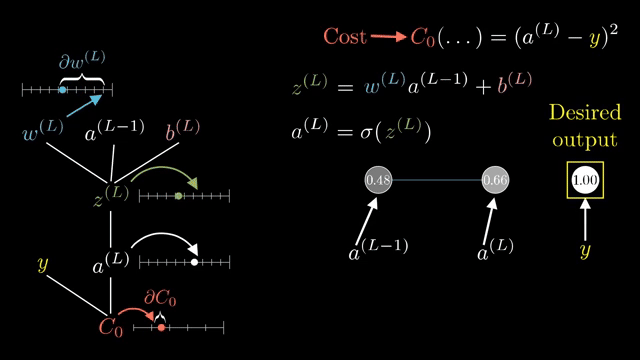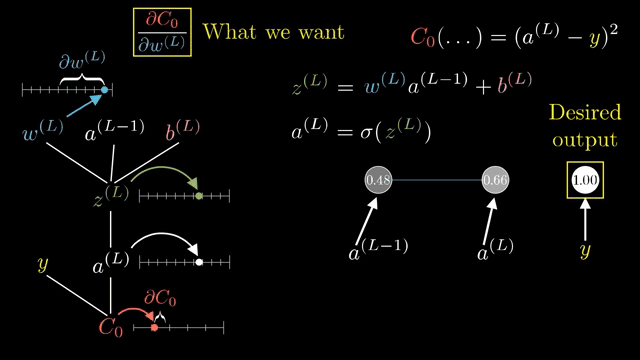
For elementwise $\sigma(z)$, the Jacobian is diagonal because output $i$ depends only on input $i$. That sparsity makes backward passes cheap: multiply upstream components by local derivatives pointwise .
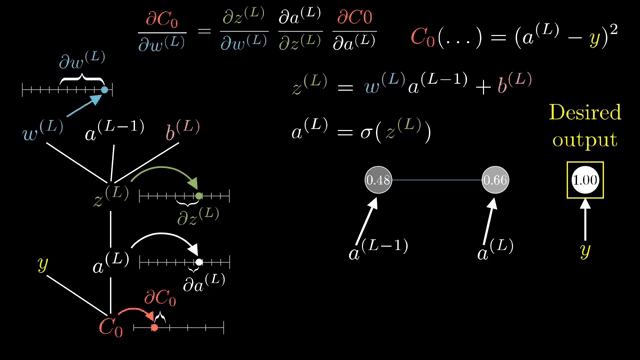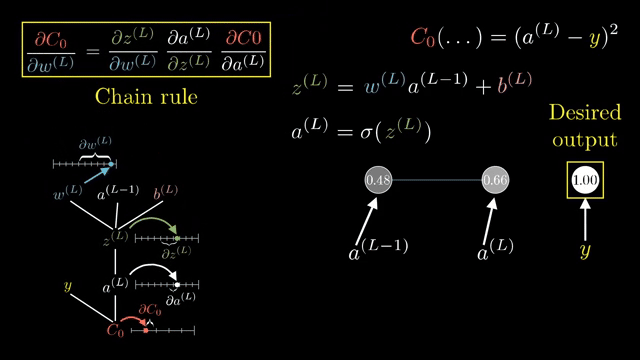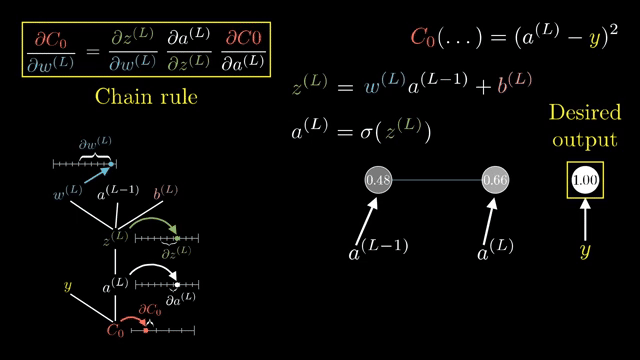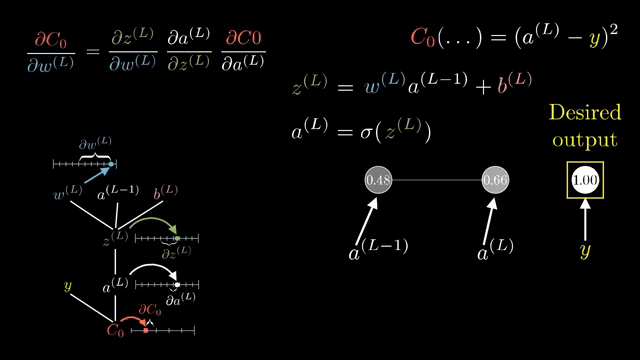
Hessian-vector products enable second-order research tricks (curvature-aware steps) without assembling the Hessian. At billion-parameter scale, even storing a dense Hessian is impossible; HVPs and low-rank approximations are the tractable path .
Explicit Hessian assembly remains uncommon in production deep learning precisely because memory scales quadratically with parameter count in the naive dense case .
Even computing the full Jacobian of a single layer w.r.t. its inputs can be enormous; backprop never asks for that matrix explicitly, only for VJPs against the upstream gradient vector carried from the loss .
Width $d$ and batch $B$ change FLOPs but not the rule: backprop always propagates a cotangent vector backward through the graph, never a full Jacobian unless you explicitly request it for analysis .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
