Worked tiny graphs before code-size graphs
Before trusting a million-line framework, trace a three-node or five-node graph by hand. The pattern repeats at scale: local partials, upstream sensitivity, multiply, sum at joins. Hand work also reveals when an operation couples every output to every input .
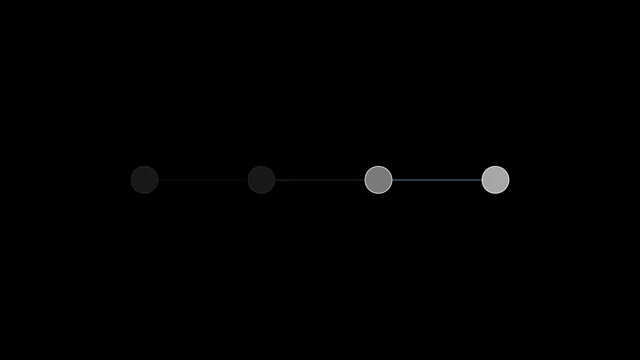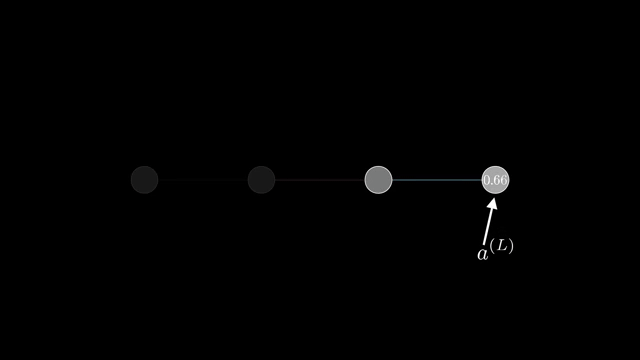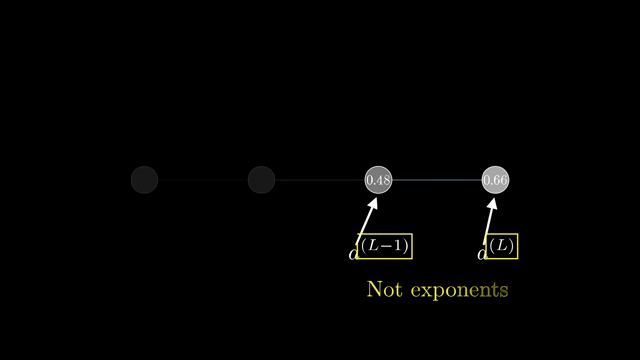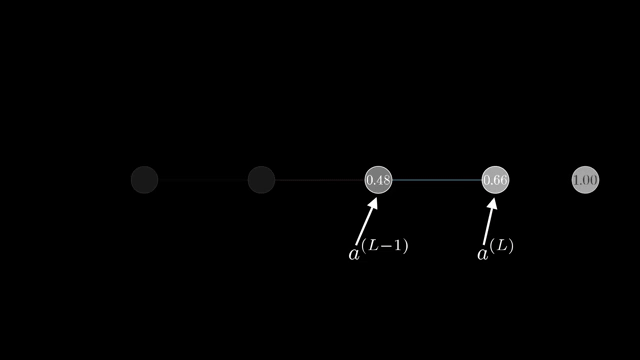
Softmax is the standard coupling example. Outputs $p_i = e^{z_i}/\sum_j e^{z_j}$ depend on all logits $z_j$, so the Jacobian $\partial p/\partial z$ is generally dense, not diagonal .
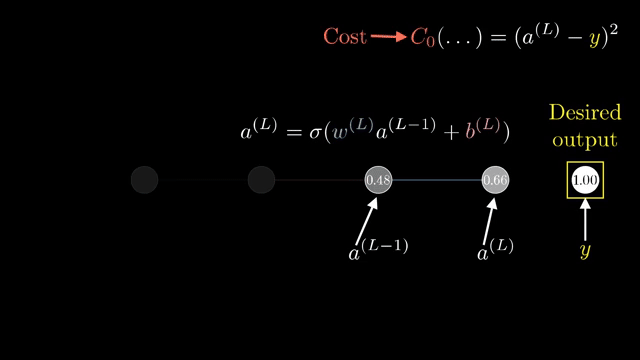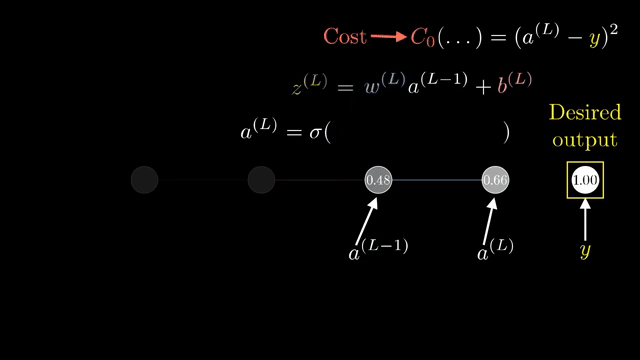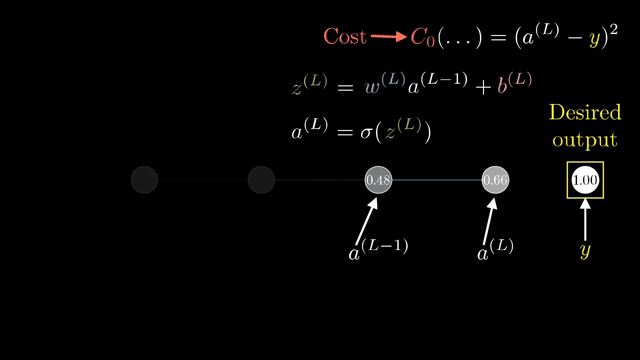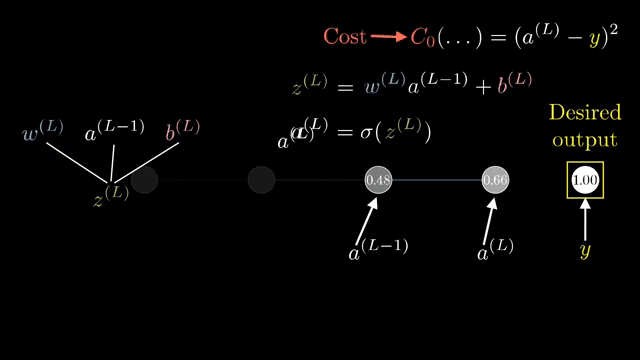
Cross-entropy with softmax yields logit gradients with the same shape as the logits themselves: one component per class error. That compact formula is what frameworks implement in fused kernels .
Broadcasting in automatic differentiation must track which axes were expanded so backward passes sum gradients over the correct dimensions. The upstream gradient at a node is the sensitivity of the final loss to an infinitesimal change in that node's output .
For a two-layer sigmoid network on MNIST, walking through one hidden unit's influence on one output logit already shows fan-out: that hidden unit feeds all ten output neurons, so its upstream gradient sums ten downstream paths .
Doing one row of the softmax Jacobian by hand shows why frameworks ship fused backward kernels: the algebra is repetitive but easy to mis-index when rushed .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
