Backprop as structured chain rule on a DAG
Training needs $\partial C/\partial w_i$ for every weight. Backpropagation organizes that bookkeeping on a computation graph: nodes are intermediate values (activations, preactivations, logits), directed edges are operations, and the forward pass evaluates the graph left to right .
Each edge carries a local derivative: how an infinitesimal change in the parent nudges the child. The chain rule multiplies these factors along any path from a weight to the cost. When a node has fan-in from several parents, contributions add; when a value fans out to several consumers, upstream gradients from each branch sum at that node .

Reverse mode walks the graph backward from the scalar cost, propagating sensitivity vectors. Because subexpressions are shared, each edge is visited once: the algorithm reuses work instead of recomputing forward passes per parameter .
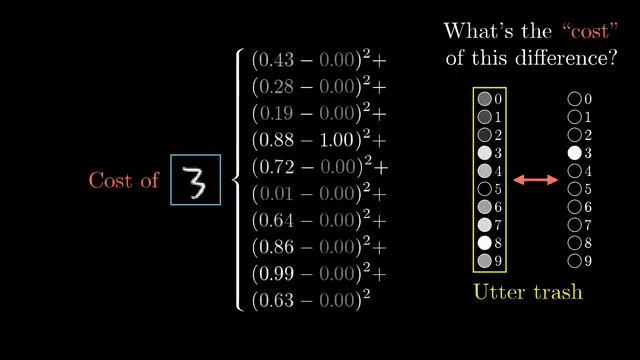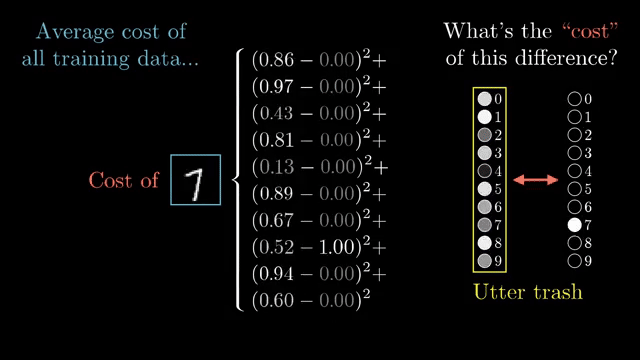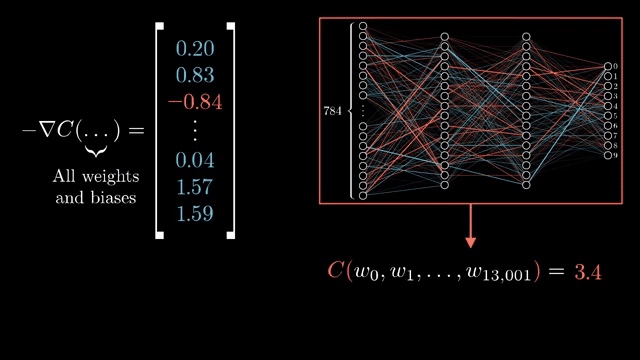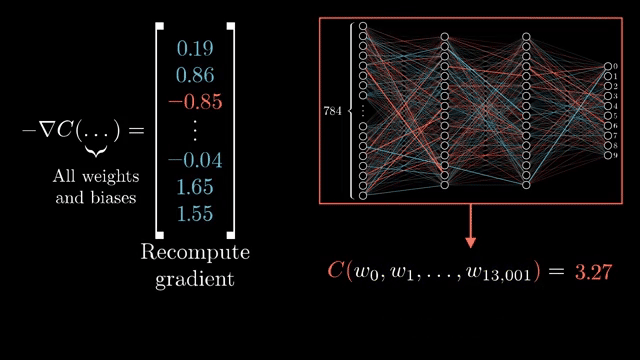
The forward pass must store activations (and sometimes masks or normalization stats) needed by backward kernels. Time is loosely one forward plus one backward pass for a fixed batch, linear in graph size, which is why backprop beats naive finite differences at scale .
The MNIST network from chapter 1 is already a deep graph if you expand matrix multiplies and activations node by node. Backprop's value is not mysticism but disciplined reuse of the chain rule on that structured graph .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
