Learning rate as step size: fragile knob
The learning rate $\eta$ controls how far each descent step moves in weight space. Too small and training crawls: thousands of tiny steps may never reach a good basin before your compute budget expires. Too large and updates overshoot narrow valleys, bouncing across the surface or diverging outright .

Picture a steep-walled ravine whose floor curves gently toward a minimum. A large $\eta$ jumps from one wall to the other each iteration, oscillating instead of sliding along the floor. A tiny $\eta$ makes progress along the floor but wastes steps on the walls. This instability is the discrete-time cousin of trying to integrate a continuous gradient flow with an oversized time step .
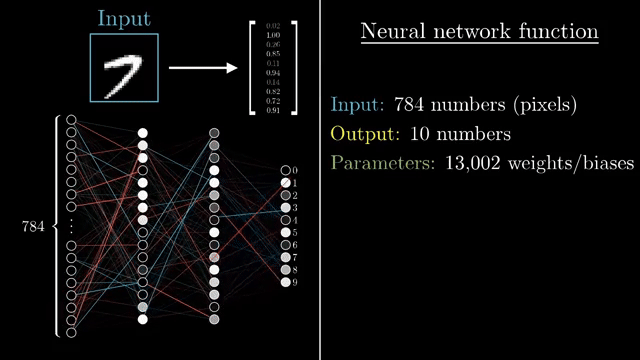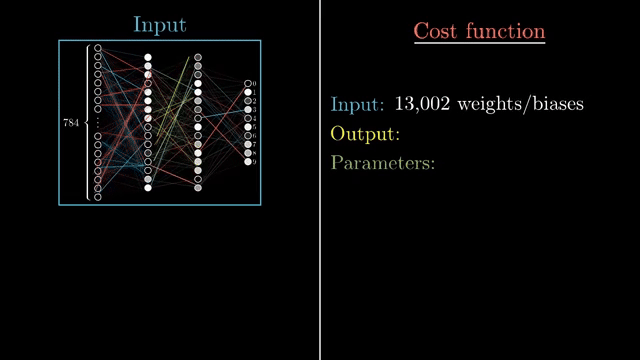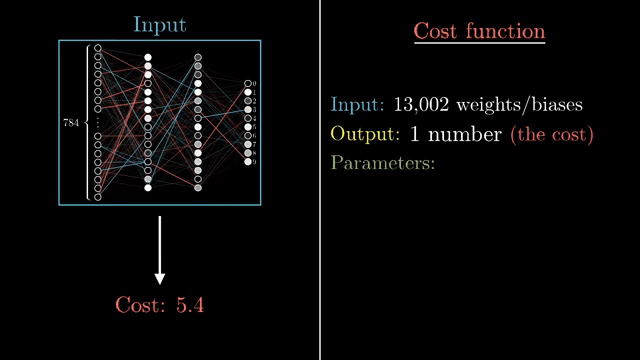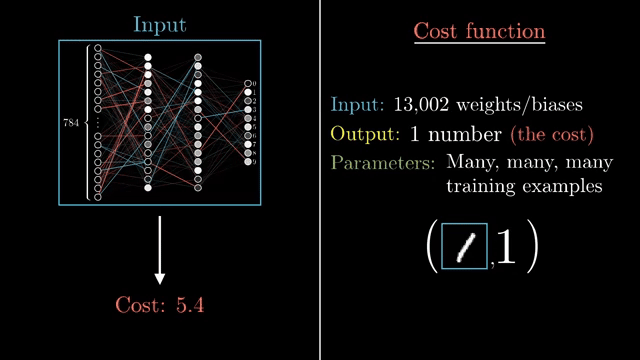
Practitioners rarely keep $\eta$ fixed forever. Learning-rate schedules decay or warm up the step size; line search methods probe a few points along the descent direction before committing. Adaptive optimizers (next card) rescale effective steps per parameter. None of these remove the core tradeoff: step size is the most fragile hyperparameter in vanilla SGD .
On MNIST-scale problems, practitioners often bracket $\eta$ with coarse grids (for example $0.01$, $0.1$, $1.0$), then refine when validation loss plateaus. Safe ranges shift with network depth, batch size, and weight initialization scale, so copying one paper's learning rate without context frequently fails .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Beginner
- Completed: 0 users
Creator
