Stochasticity: minibatches approximate the full-data gradient
Exact gradient descent recomputes $\nabla C$ using every training example each step. For MNIST that is tolerable; for web-scale corpora it is not. Stochastic gradient descent (SGD) estimates the gradient from a mini-batch: a small random subset of examples drawn each iteration .
If the full-data gradient is $\mathbf{g}$, a batch gradient $\hat{\mathbf{g}}$ is a noisy draw whose expectation equals $\mathbf{g}$ under uniform sampling. The noise variance shrinks as batch size grows, but wall-clock per step rises because each example still needs a forward and backward pass .
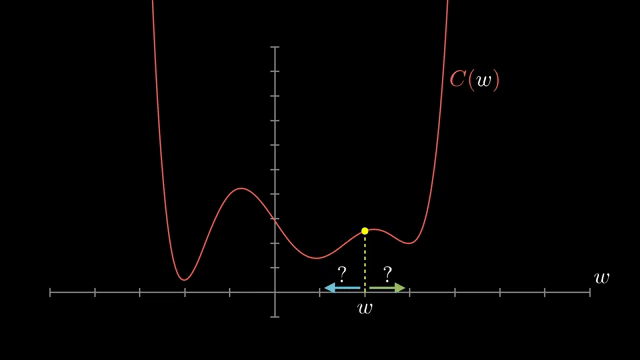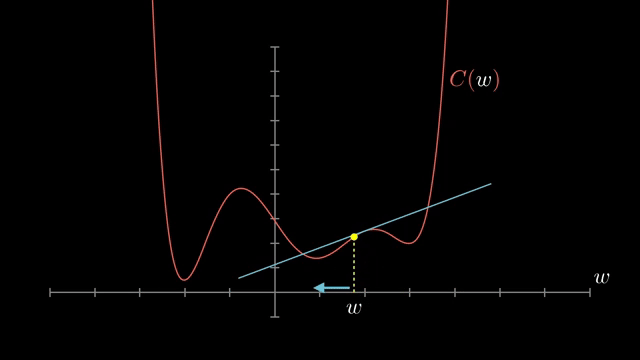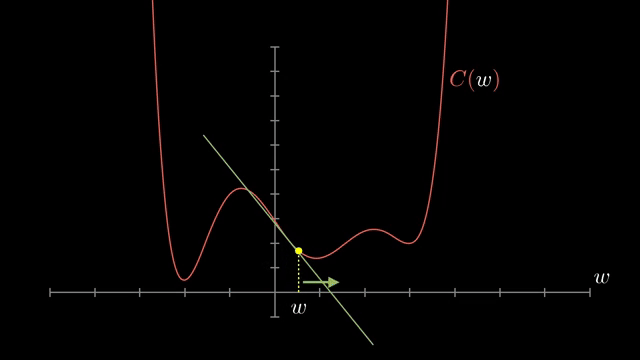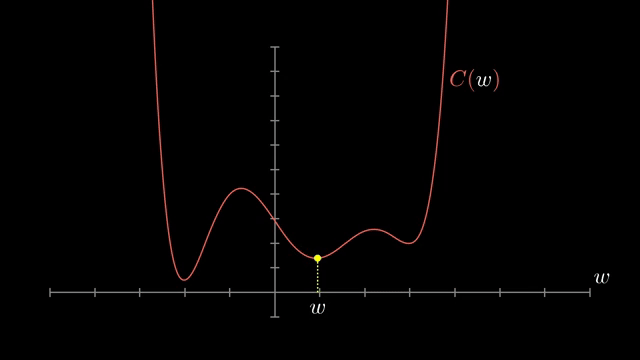
An epoch is one pass through the training set under whatever sampling schedule you use. Shuffling between epochs reduces order bias: without it, consecutive batches might systematically skew the noise direction. Batch size therefore trades variance of gradient estimates against throughput per update .
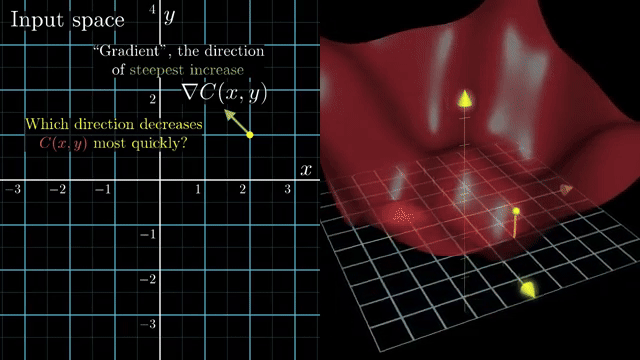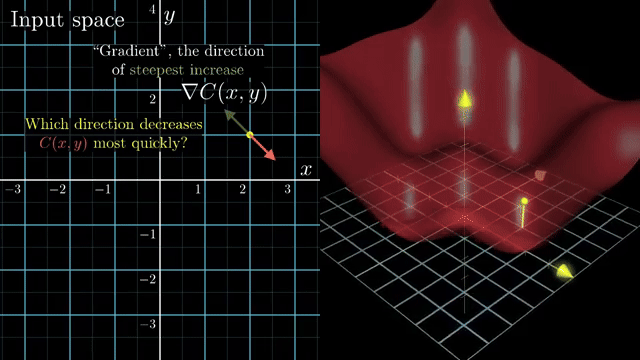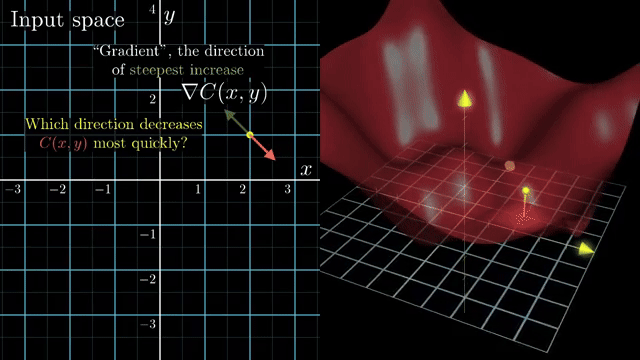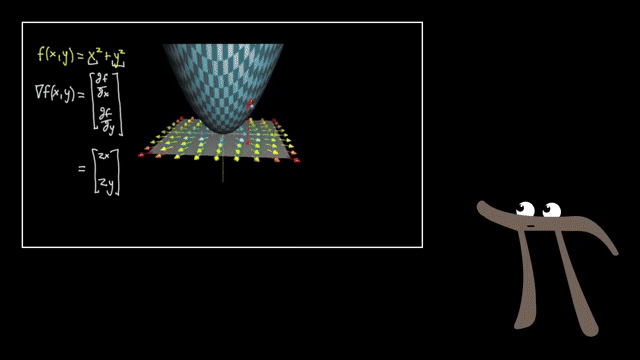
Small-batch noise is not purely harmful. It can nudge iterates out of shallow basins and flat regions, acting like implicit regularization in some regimes. Large batches give cleaner gradient signals but may need learning-rate retuning to preserve similar training dynamics .
The digit-classification example processes batches of tens of images per step rather than all 60{,}000 MNIST points at once. That choice makes each epoch affordable while preserving enough noise that optimization does not freeze on the first shallow basin it encounters .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Beginner
- Completed: 0 users
Creator
