Pedagogical edge cases: saturation, dead ReLUs, initialization
The closing interview contrasts historical sigmoid activations, motivated by biological on/off neurons, with modern ReLU units $\max(0,a)$ that pass positive preactivations through unchanged and zero out negative ones . Sigmoid and tanh saturate: derivatives near 0 shrink backpropagated signal, which hurts very deep training (vanishing gradients). ReLU's constant slope on the active half-line eased optimization for deep stacks in practice .
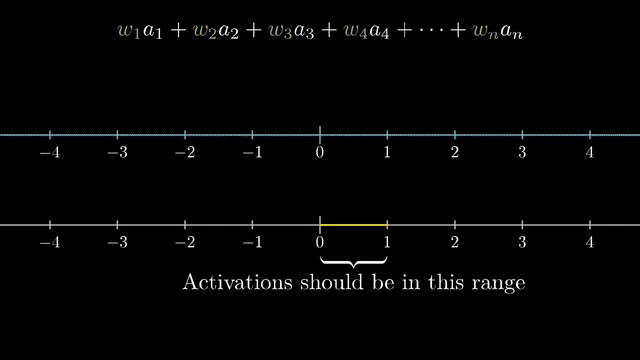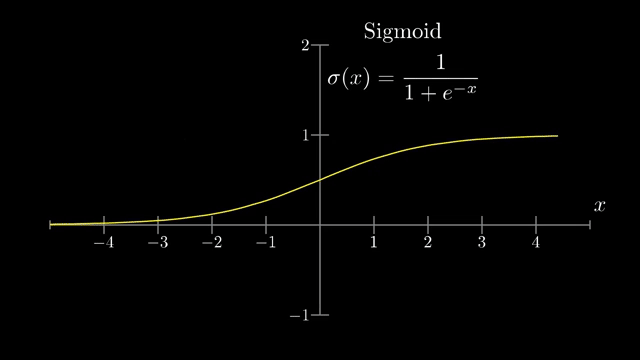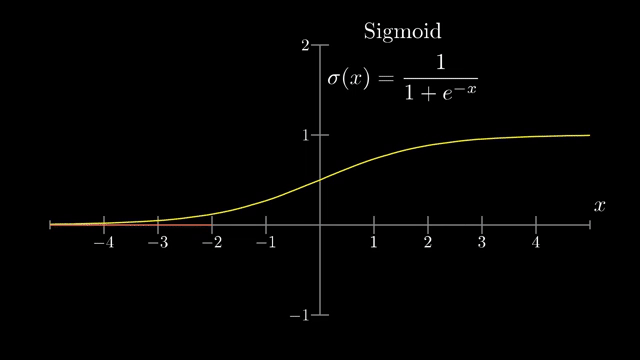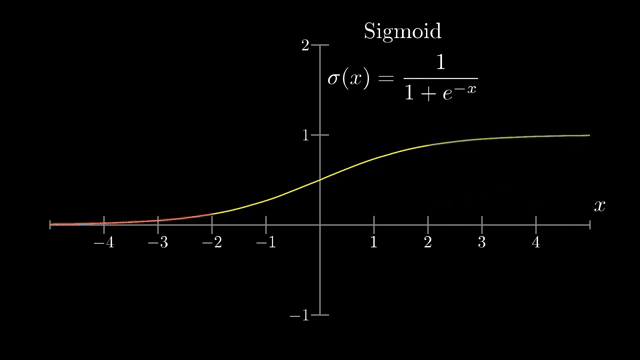
ReLU has its own failure mode: if weights and biases push a unit's preactivation permanently negative for the training inputs you care about, the neuron outputs zero and receives zero gradient, a dead ReLU. Initialization schemes (Xavier/He) scale random weights with layer width so activations and gradients do not explode or vanish at startup .
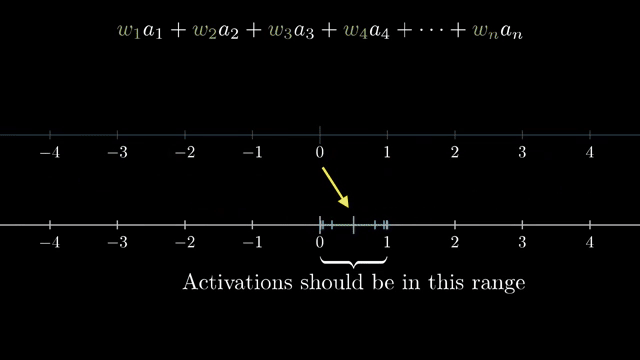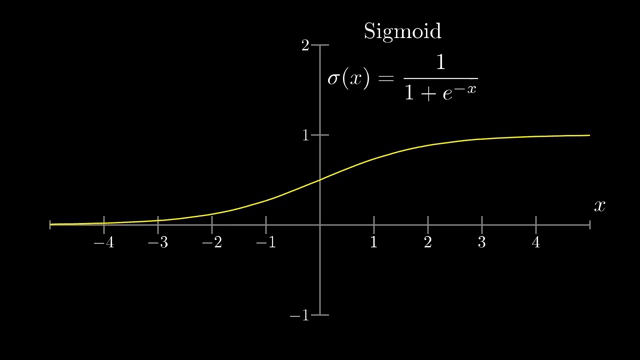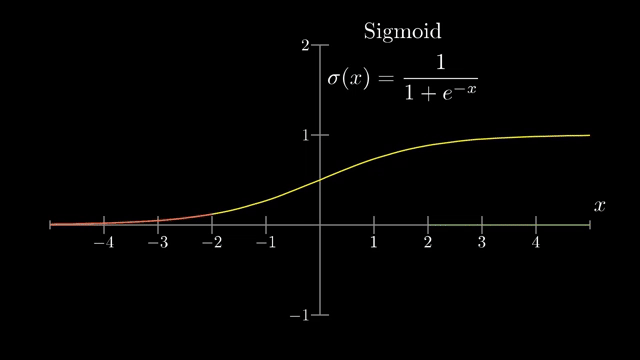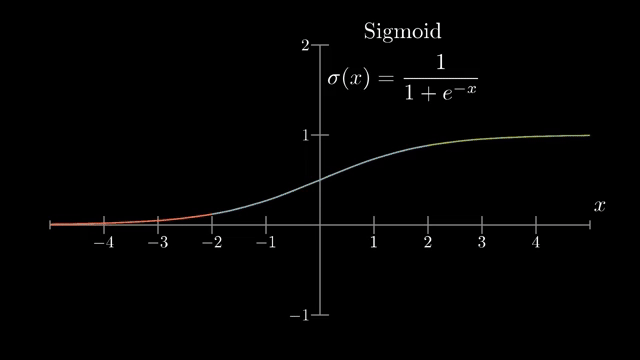
Batch normalization (a later technique) standardizes intermediate activations during training batches, often stabilizing optimization; it does not remove gradients or linearize the model. Practitioners also watch validation metrics, calibration plots, and failure modes under shift, not only the training loss curve .
Finally, training loss decreasing is necessary but not sufficient for a production-ready system. You still need checks for robustness, calibration, bias, and behavior under distribution shift .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Beginner
- Completed: 0 users
Creator
