Classification heads and probabilistic outputs
The output layer presents ten competing scores, one per digit. For probabilistic training we often write those scores as a vector of logits $\mathbf{z}\in\mathbb{R}^{10}$ and apply softmax:
$$\mathrm{softmax}(\mathbf{z})_k = \frac{e^{z_k}}{\sum_j e^{z_j}}.$$
Softmax outputs are nonnegative and sum to 1, so they behave like a categorical distribution over classes .

Adding the same constant to every logit multiplies numerator and denominator by the same factor, so softmax is unchanged; only relative differences matter. Multiplying all logits by a positive scalar preserves their order, so argmax predictions stay the same even though probabilities stretch or compress .
Training with cross-entropy compares the softmax probabilities to a one-hot label vector and pushes mass onto the correct class while suppressing others, gradients with respect to logits are largest when the model is confidently wrong . In the digit demo, the brightest output activation after a forward pass is the network's guess; softmax training makes that competition explicit as a probability vector rather than an informal brightness contest.
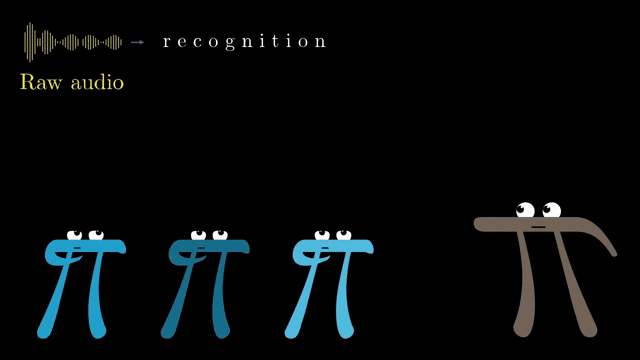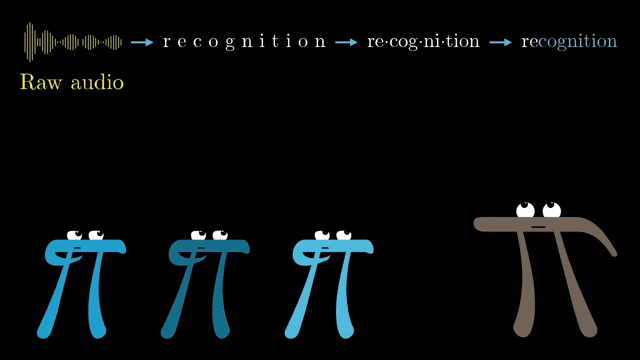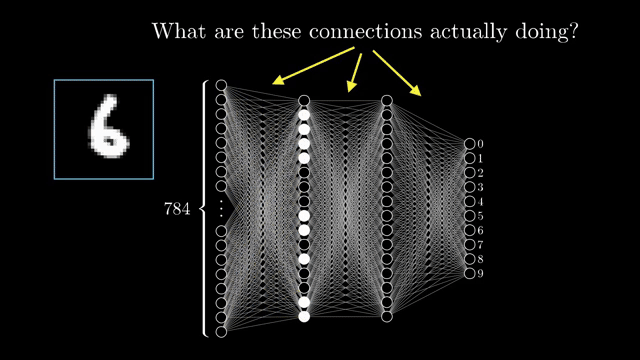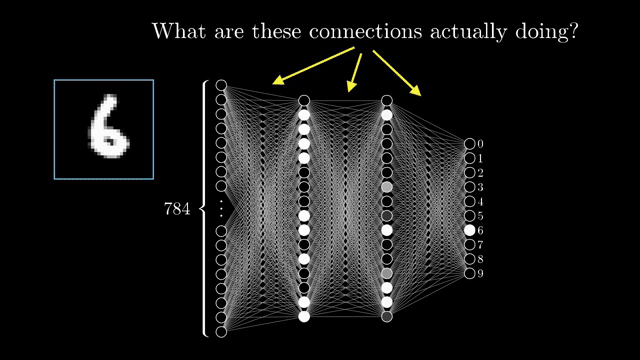
Edge case: softmax of the all-zero vector gives the uniform distribution with each class probability $1/K$, maximum uncertainty when every logit ties.
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Beginner
- Completed: 0 users
Creator
