Neurons: weighted sums, bias, then a nonlinearity
This chapter poses a core design question: given activations in one layer, what knobs let a network combine pixels into edges, edges into loops, and loops into digits? The answer in this chapter is deliberately small: each neuron holds one number (its activation), typically between 0 and 1, and the next layer is built from weighted sums of those numbers .
Fix one neuron in the second layer that should respond to a local pixel pattern. Every connection from the input layer carries a weight (positive or negative). The neuron computes the weighted sum of upstream activations; weights play the role of dials: near-zero weights ignore pixels, large magnitudes amplify them, and mixed signs let the unit prefer bright centers with darker surroundings, an edge detector in prose .
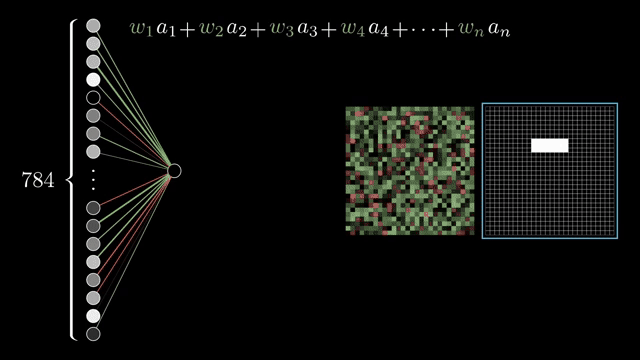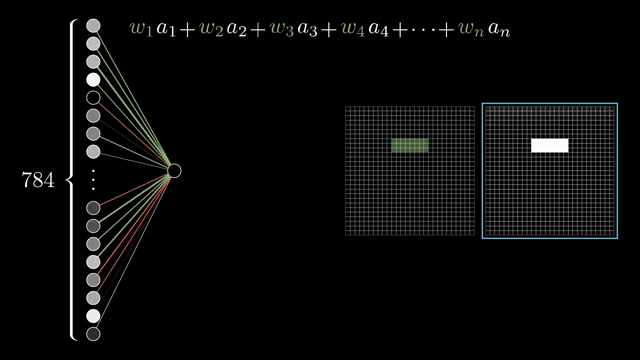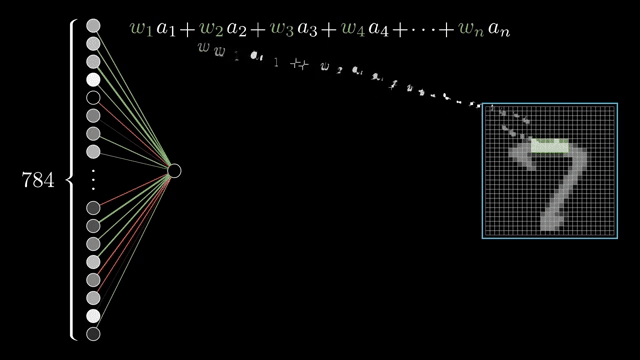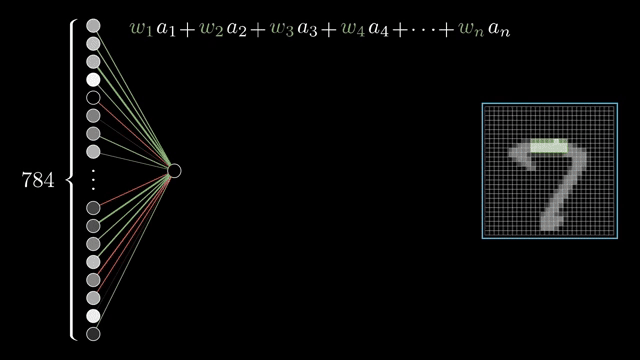
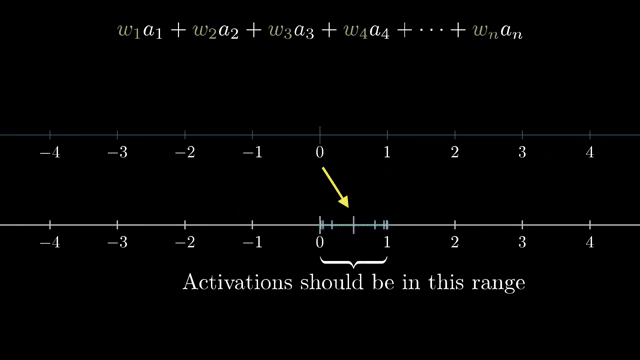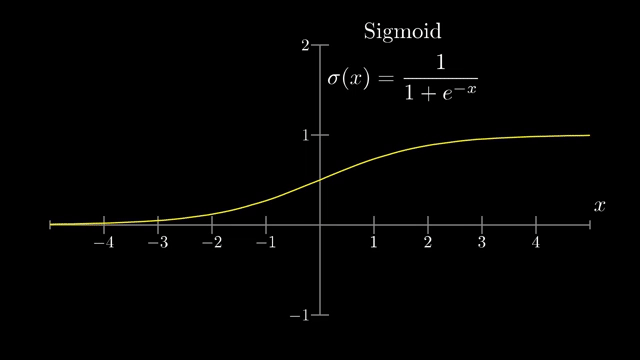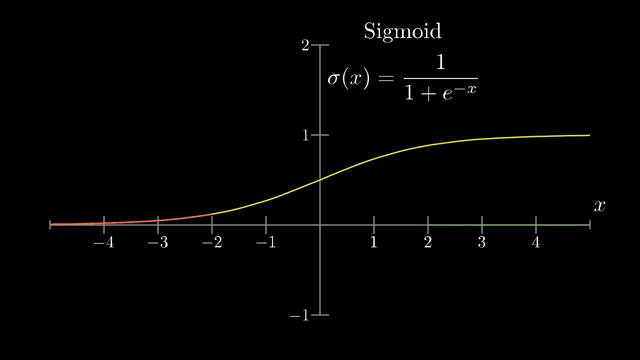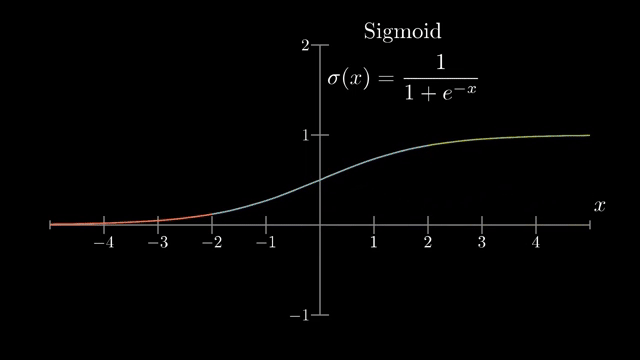
Raw weighted sums live on the entire real line, but the story wants activations that stay in $[0,1]$. The network pumps the sum through a squashing function; the classical choice is the sigmoid (logistic curve): large negative inputs map near 0, large positive inputs map near 1, with a smooth transition through 0 .
Not every neuron should fire on a tiny positive sum. Add a bias, an extra constant added before the nonlinearity, so the unit stays inactive until the weighted evidence crosses a threshold you choose (a common teaching example is "add $-10$ before sigmoid" as a concrete picture). Weights encode which pattern; bias encodes how much evidence is enough .
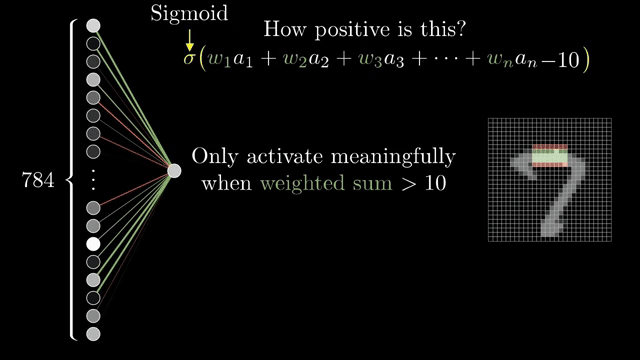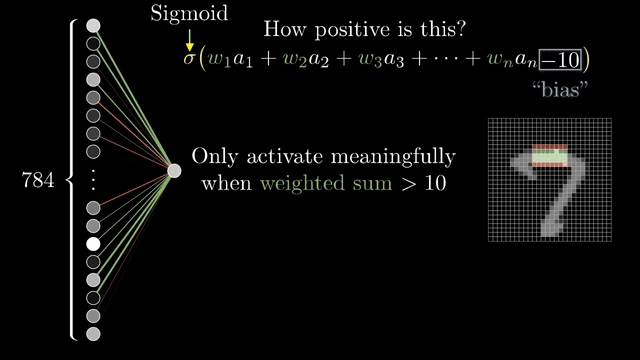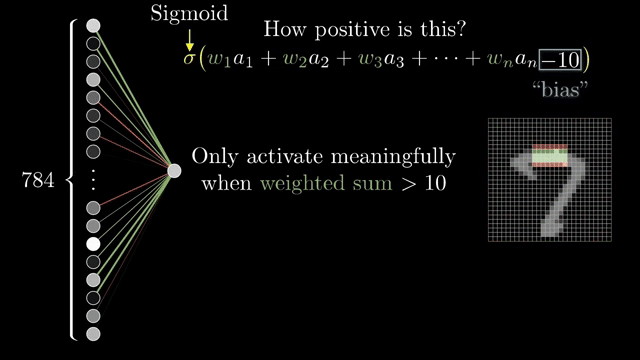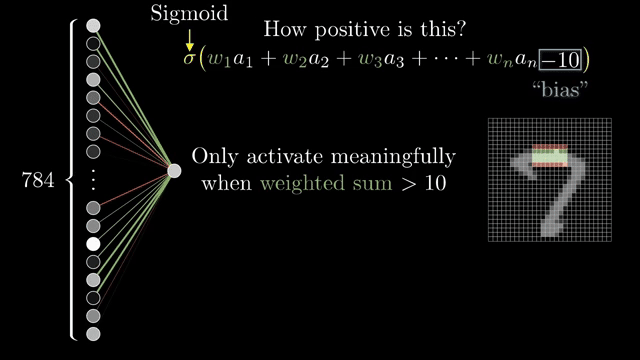
Stack many such units and you get a feedforward pass: activations flow from inputs toward outputs with no cycles during prediction. Without nonlinearities between affine blocks, depth collapses. Composing linear maps is still one linear map, so the sigmoid (or ReLU later) is what makes depth meaningful rather than redundant.
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Beginner
- Completed: 0 users
Creator
