Information of language
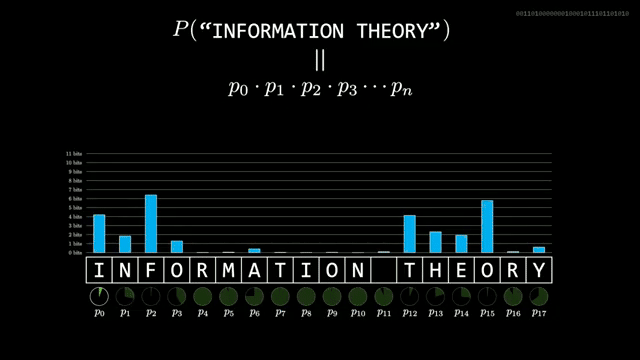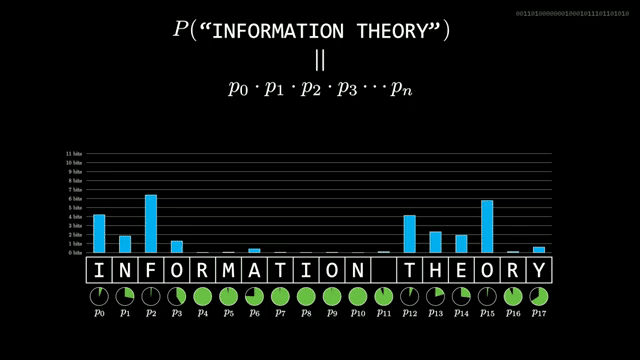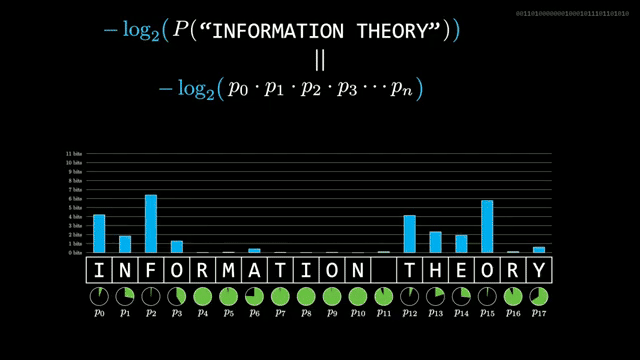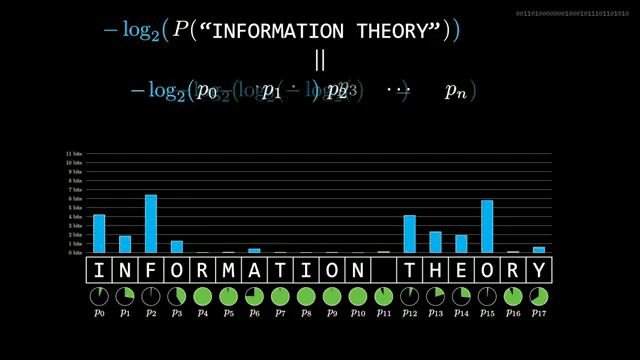
English letter frequencies are wildly skewed; assuming twenty-six equally likely letters wastes about $\log_2(26)$ bits per character . Letters are not independent: after th you expect vowels, and wider context lowers the information of the next symbol further.

Given a predictor that assigns $p$ to the symbol that occurs, the realized information is $-\log_2 p$. Average that over a long sample to estimate entropy rate. Shannon's human guessing experiments suggested about one bit per English character, far below naive letter counts .
Modern tokenized language models report cross-entropy as expected bits per token, but the arithmetic is unchanged: unlikely tokens cost more bits. Approaching language's compression limit requires predictors close to the true generative probabilities .
Related cards
Video Content
Tasks
Card Info
- Topic: Information theory, 3Blue1Brown
- Difficulty: Intermediate
- Completed: 0 users
Creator
