Compression limits and the intelligence slogan
Text can always be encoded more compactly than fixed-width ASCII: frequent symbols deserve shorter bit patterns, and longer regularities in prose can be exploited still further. The question is whether a ceiling exists at all .
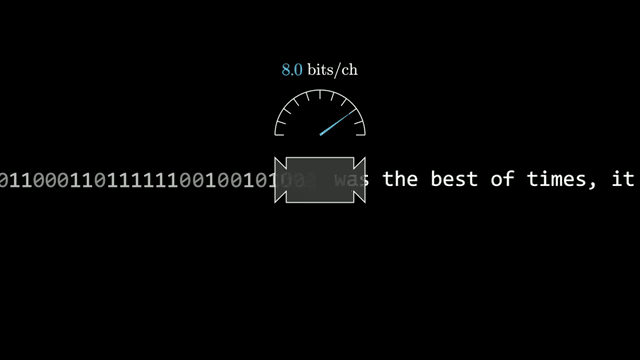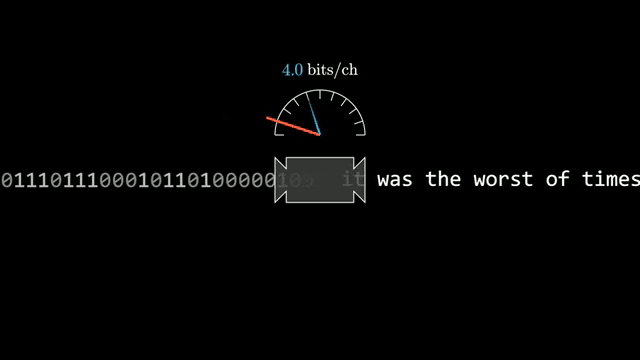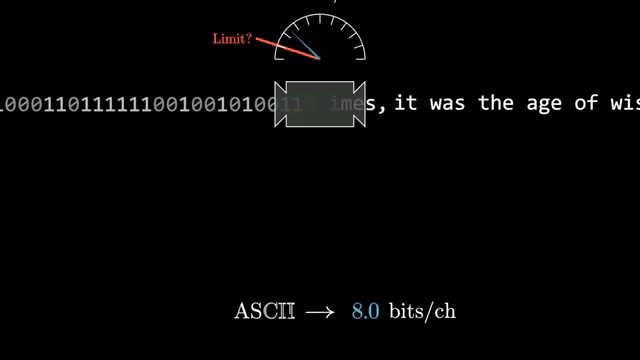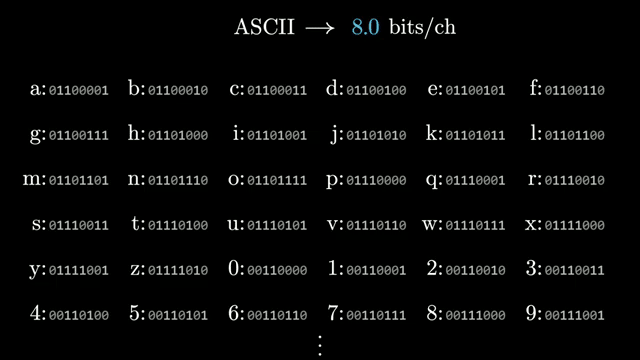
Claude Shannon's work turned that puzzle into information theory. Modern language-model pre-training is usually described as next-token prediction with cross-entropy loss, yet the same mathematics links prediction and compression: a model that assigns accurate probabilities is implicitly a compressor .
The slogan compression is intelligence is provocative because "intelligence" is vague, but the concrete claim is that compression math keeps reappearing in AI. This lecture rediscovers definitions of information and entropy by asking what optimal coding must look like, not by memorizing formulas first .

Related cards
Video Content
Tasks
Card Info
- Topic: Information theory, 3Blue1Brown
- Difficulty: Intermediate
- Completed: 0 users
Creator
