Guest bridge: from classical optimization to generative stacks
Welch Labs extends the playlist's visual vocabulary toward image and video synthesis. The same autodiff tooling that trained small feedforward nets now sculpts generative dynamics: latent spaces, noise schedules, and learned decoders [2].
Generative models learn distributions over high-dimensional data, not single deterministic labels. Latent variables compress observations into lower-dimensional coordinates before decoding back to pixels or frames [2].

Welch Labs walks the same visual style as the earlier MNIST chapters but targets pixels and frames instead of digit labels [2].
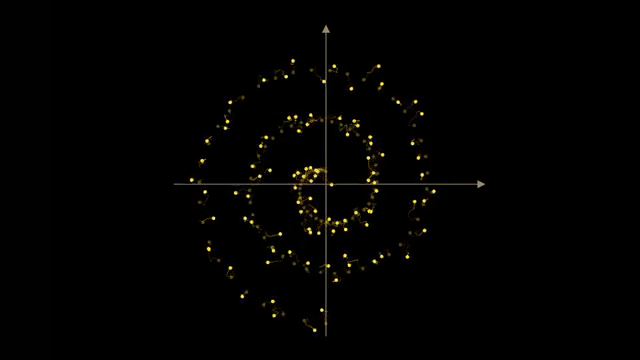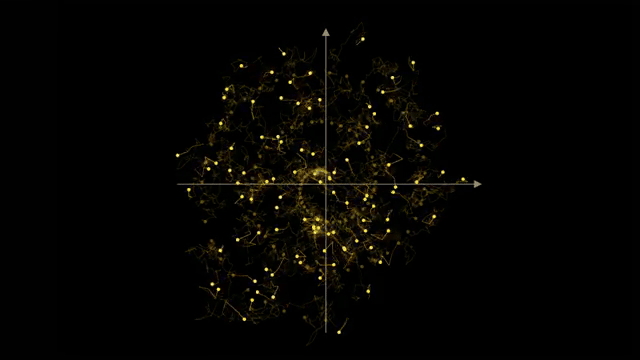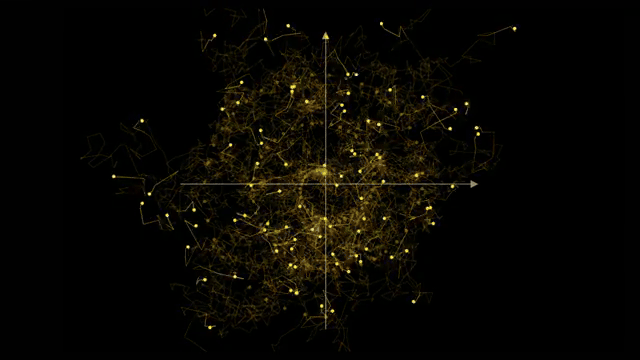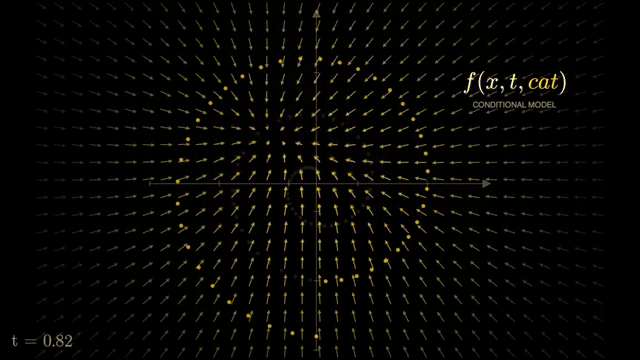
The episode complements MNIST chapters by showing another frontier where gradients optimize objectives beyond classification accuracy .
Generative stacks reuse autograd machinery from classification: loss on noise prediction backpropagates through U-Net or transformer blocks. The difference is the objective and iterative sampler at inference, not the absence of gradients [2].
Latent diffusion (Stable Diffusion-style) runs the denoising U-Net in a compressed VAE space, reducing compute versus pixel-space diffusion at similar perceptual quality [2].
VAE encoders map pixels to latents with a KL penalty toward a simple prior; decoders reconstruct images from sampled latents. Diffusion then operates in that smoother geometry rather than raw RGB grids .
Sources
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
