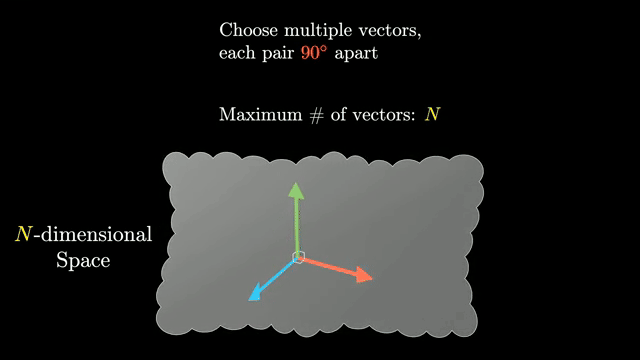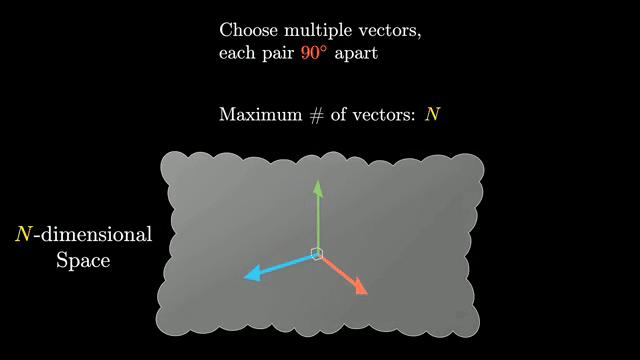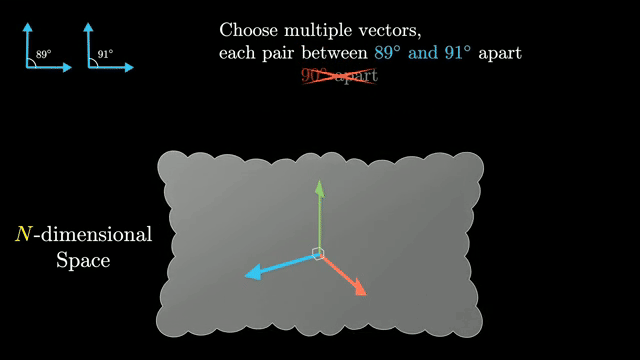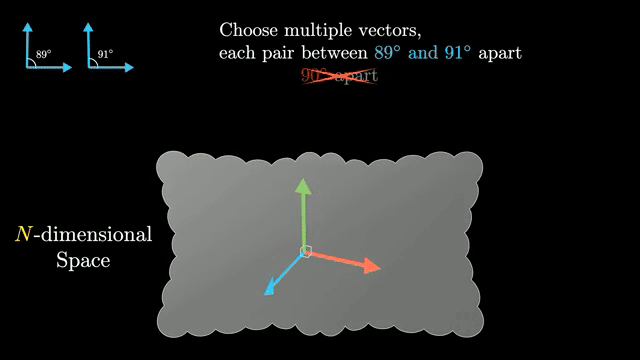
Knowledge editing and limits of surgical updates
Can you patch one fact without retraining? Methods like ROME and MEMIT attempt localized weight edits to change specific associations. Success is partial: related prompts may flip while unrelated behavior drifts .
ROME-style edits locate a small set of MLP weights associated with a relation direction in activation space; MEMIT extends the idea to multiple layers. Both assume linear structure that may not hold under prompt shift .
Side effects propagate because weights are entangled; editing "capital of France" may touch representations shared with geography, history, or French language statistics . Model cards document intended use, limitations, and evaluation coverage for transparency .

Red teaming adversarially probes harmful behaviors before deployment. "Open the black box" via interpretability is incomplete for certification: artifacts rarely cover all behaviors under shift, attack, or long-horizon misuse without holistic measurement . Regulated domains may still require full retraining plus governance, not surgical patches .
Editing benchmarks test persistence under paraphrase. High success on a narrow template can still fail on compositional questions that stress related concepts in superposition .
Governance for regulated domains may forbid silent weight edits entirely, requiring audited retraining pipelines with dataset lineage instead of MEMIT-style patches .
Post-edit evaluation should include neighboring facts, multilingual prompts, and adversarial paraphrases, not only the single template used during the edit .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Advanced
- Completed: 0 users
Creator
