Efficient attention approximations (concept map)
Full softmax attention costs $O(n^2)$ per layer in sequence length. When $n$ reaches tens of thousands, quadratic memory and compute dominate. Research explores approximations that trade fidelity for subquadratic cost .
Linear attention methods replace softmax with kernel feature maps so attention becomes an associative scan in $O(n)$. Sparse patterns attend only to fixed or learned subsets of positions. Linformer, Performer, and Nyström variants compress the key-value sequence or approximate the attention matrix .
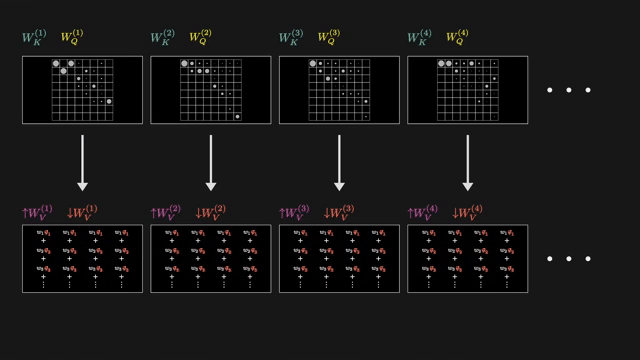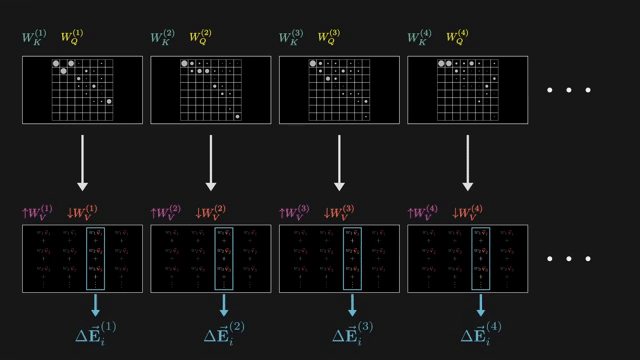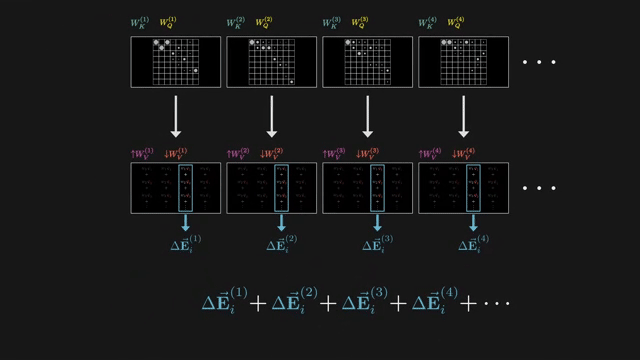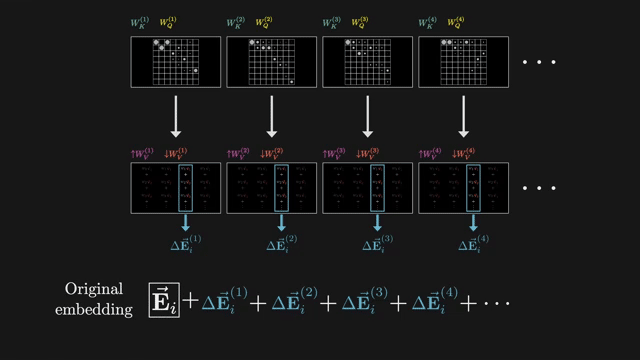
State space models (S4, Mamba) use structured recurrent linear dynamics as an alternative sequence mixer with $O(n)$ inference scaling on long sequences . Hybrid stacks combine attention in some layers with SSM or convolution in others.

Frontier models still use full attention in many layers because global mixing remains hard to match with aggressive sparsity without quality loss on some tasks. The choice depends on sequence length distribution, hardware, and evaluation budget .
When evaluating sparse or linear attention, measure perplexity on long documents, not only wall-clock speed. Approximations that look fine on short prompts can fail where global mixing matters .
Hybrid models may use full attention in early layers for global layout and sparse attention deeper in the stack; ablations should report quality per layer group, not only aggregate benchmarks .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Advanced
- Completed: 0 users
Creator
