Masking bugs and leakage
Two mask families appear in almost every codebase. Padding masks zero out attention to padded positions in variable-length batches; those slots carry no semantic content . Causal masks set scores to $-\infty$ (or a large negative) for future positions $j \gt i$ before softmax, enforcing autoregressive visibility .
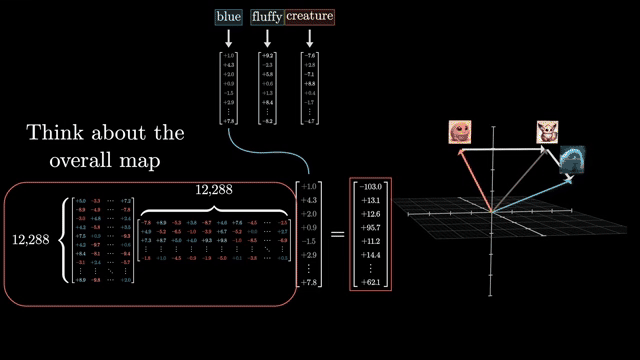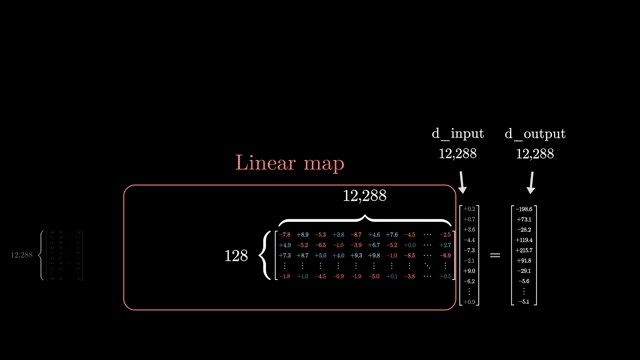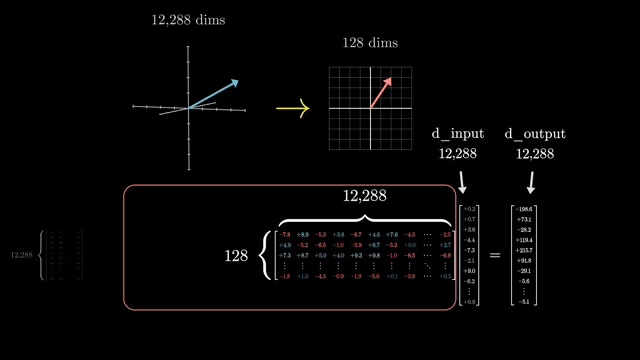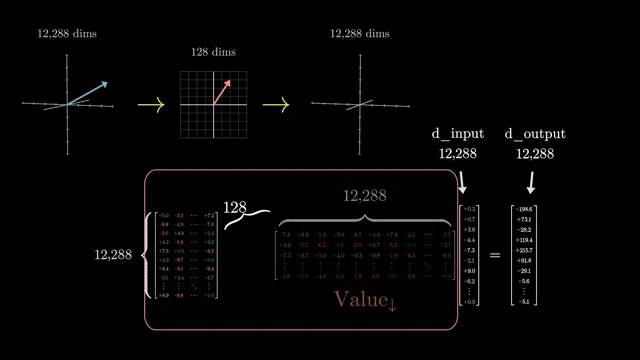
Swapping masks is catastrophic. Padding mask on a causal decoder lets the model attend to future real tokens; causal mask on a BERT encoder blocks useful bidirectional context. Each objective requires a matching mask and inference protocol .
Sliding-window (local) attention restricts each token to a neighborhood of width $w$, reducing $O(n^2)$ cost. Custom boolean masks define which $(i,j)$ pairs are allowed; implementation bugs often show up as sudden validation loss drops that trace to label leakage .
Regression tests should include padded and unpadded batches to ensure mask broadcast matches both shapes. Causal and padding masks compose by adding large negatives to forbidden cells before a single softmax .
Log maximum attention mass on padded positions during training; any positive mass indicates a mask leak that will hurt validation perplexity in subtle ways .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Advanced
- Completed: 0 users
Creator
