Tensor programs: batch × heads × sequence × dim
Production attention is a stack of GEMMs (general matrix multiplies) on GPU. Typical shapes: batch $B$, heads $h$, sequence $n$, head dimension $d_h$. Queries might live in $\mathbb{R}^{B \times h \times n \times d_h}$ before scores are formed by contracting the last dimension of $Q$ with $K$ .
Broadcasting errors across the head dimension pair the wrong query head with the wrong key head, scrambling outputs silently. Always verify tensor strides and einsum indices when debugging .
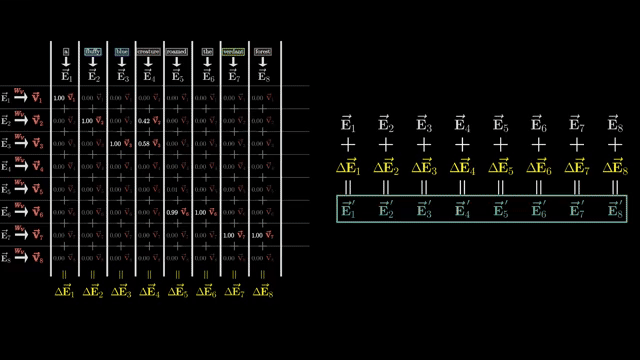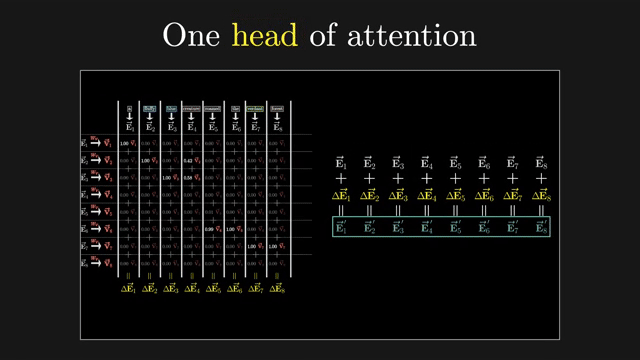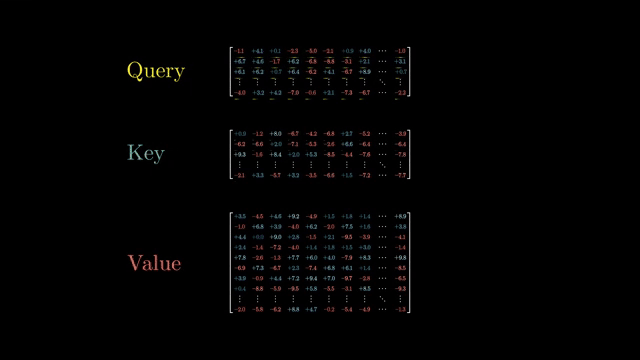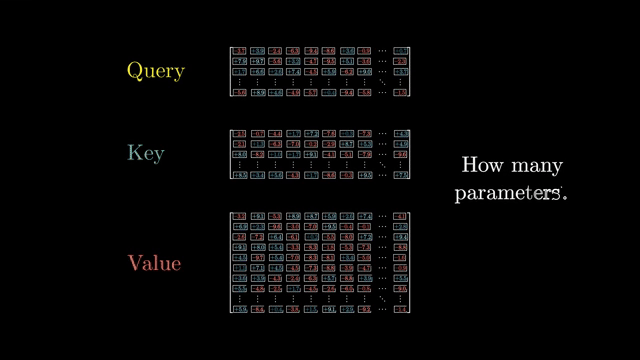
FlashAttention fuses tiled matrix multiply with softmax inside GPU SRAM, reducing round-trips to high-bandwidth memory (HBM). It recomputes some intermediates in backward pass rather than storing the full $n \times n$ attention matrix, trading compute for memory . Tiling keeps blocks of queries and keys resident in fast memory while accumulating softmax statistics blockwise .
Profile attention on real hardware: naive $O(n^2)$ materialization may be memory-bound before compute-bound. FlashAttention-style kernels change the bottleneck; low SM utilization often means fused attention is the fix rather than a wider model .
When porting to another framework, re-derive einsum indices on paper before trusting an auto-translated graph. Head and batch axes are the usual swap that passes shape checks but fails semantics .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Advanced
- Completed: 0 users
Creator
