Differentiable key-value lookup view
Attention can be read as a soft dictionary lookup. Keys index rows of a memory table; values store content; queries ask which rows to retrieve. Hard argmax attention picks one index (usually non-differentiable); softmax attention blends many rows with differentiable weights .
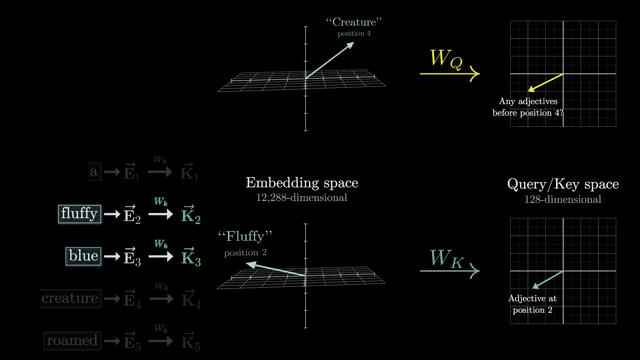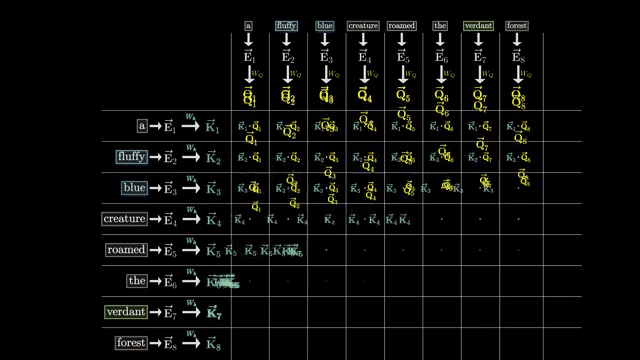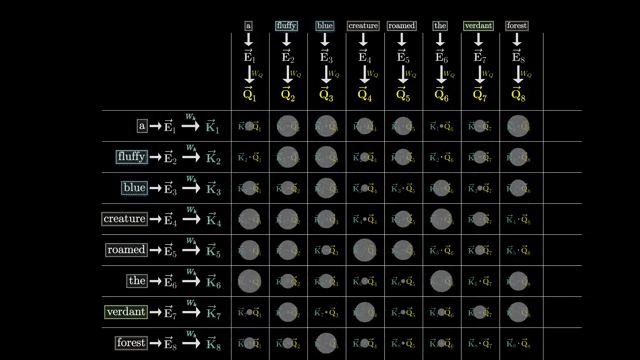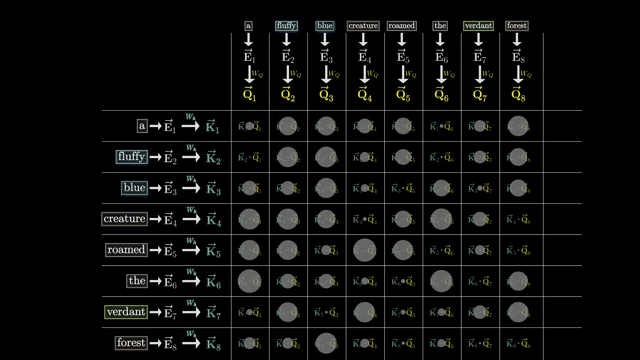
Dot-product scores measure compatibility between query and key directions in the head subspace. If $Q_i$ and $K_j$ are nearly orthogonal, the raw score is small and position $j$ receives little mass unless other terms (positional bias, scaling) dominate .
Some architectures multiply attention outputs by learned gates (sigmoid or similar) to suppress heads dynamically. The core lookup picture still applies: queries route information from a pool of value vectors .
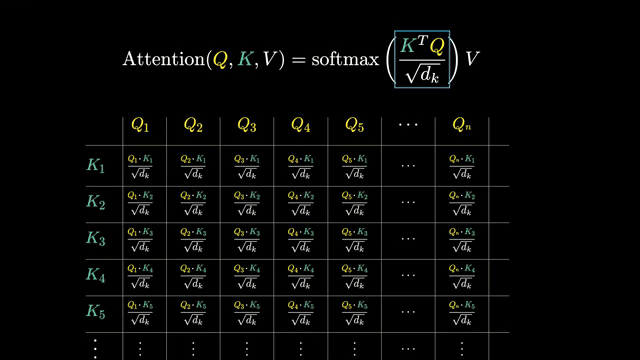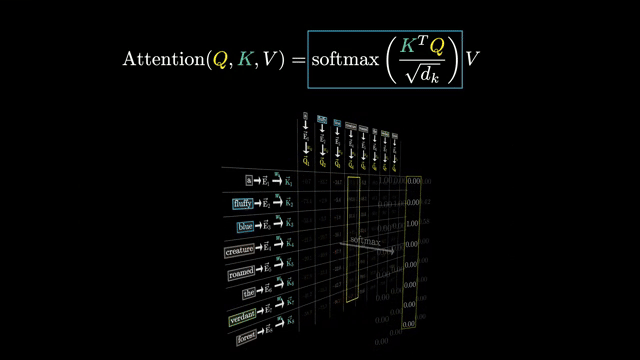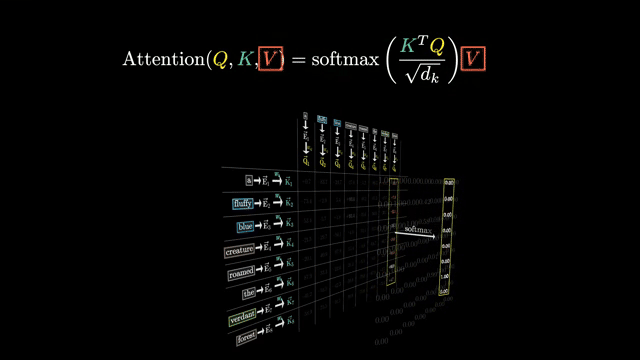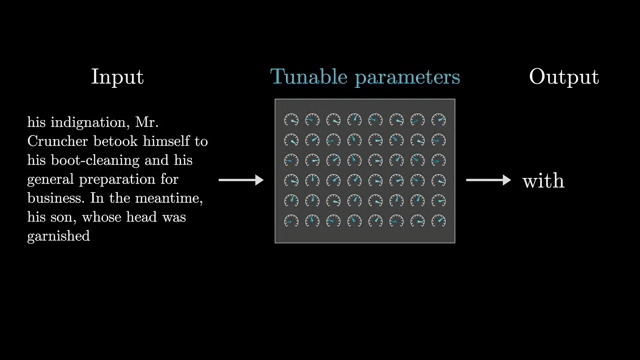
This view explains why attention excels at long-range dependencies: any query can reach any key in one hop, unlike RNNs that propagate signal through $O(n)$ sequential steps .
The lookup metaphor breaks if values are identical across positions: softmax weights still mix, but the output equals that shared vector regardless of query. Upstream MLP layers create the value diversity that makes attention nontrivial .
Compare softmax attention to hard attention on the same toy keys: the soft output is smoother and trainable, which is why transformers use softmax even though hard routing looks cleaner in diagrams .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Advanced
- Completed: 0 users
Creator
