Score matrix and softmax along keys
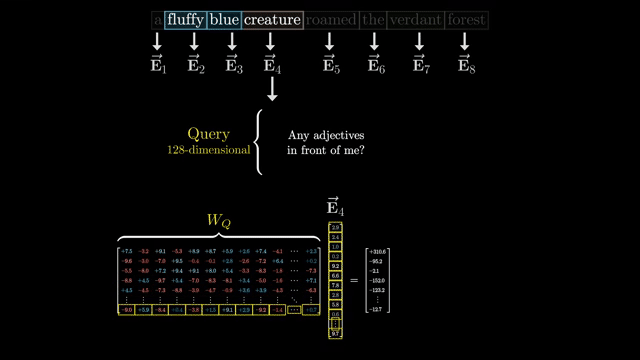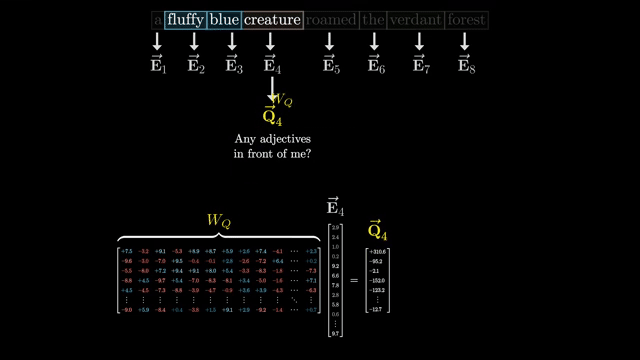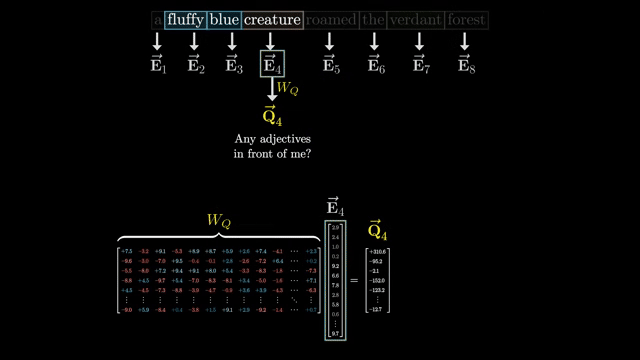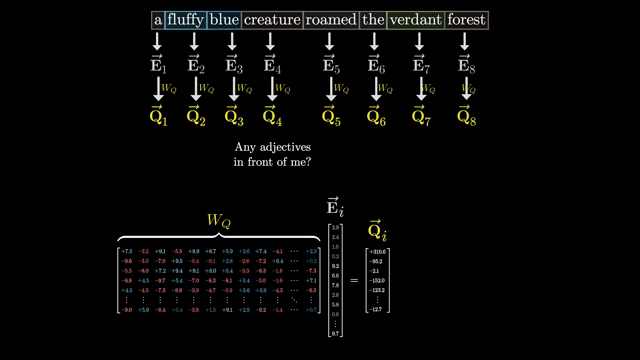
Stack all query-key scores into a matrix $S \in \mathbb{R}^{n \times n}$ with $S_{ij} = Q_i \cdot K_j / \sqrt{d_k}$. For each row $i$ (fixed query), apply softmax across columns $j$ (keys):
$$\alpha_{ij} = \frac{e^{S_{ij}}}{\sum_k e^{S_{ik}}}.$$
Each row lies on the probability simplex: entries are nonnegative and sum to 1 .

The attention output matrix is $A V$ where $A$ is the softmax-normalized score matrix. In batched multi-head form, the same pattern repeats independently per head and batch item .
Numerical stability matters in FP16: if scores drift too large, softmax saturates to one-hot rows and gradients vanish; if scores collapse, rows become nearly uniform and attention fails to focus. The $\sqrt{d_k}$ scaling is one guardrail . Dropout on attention weights during training randomly zeroes some $\alpha_{ij}$, a mild regularizer in some architectures .
Temperature on attention logits is rarely used in standard transformers, but the softmax saturation story still helps debug collapsed rows: if all mass lands on one key, inspect whether $d_k$ scaling was omitted or fp16 overflow clipped the logits .
Visualize attention rows for a single head on a short sentence: you should see mass concentrate on syntactic dependents and repeated tokens. Uniform rows signal a bug or a dead head worth pruning in analysis .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Advanced
- Completed: 0 users
Creator
