Training stability at scale
Training billion-parameter transformers is as much engineering as theory. AdamW decouples weight decay from Adam's adaptive learning-rate correction, a standard optimizer for LLM pretraining . Gradient clipping caps global norm before the update step, preventing occasional loss spikes from exploding weights in deep stacks .
Mixed precision (FP16 or BF16) cuts memory and increases throughput; loss scaling multiplies the loss before backward pass so tiny gradients remain representable in low precision . Gradient accumulation sums gradients over micro-batches, simulating larger effective batch sizes when GPU memory cannot hold the full batch .
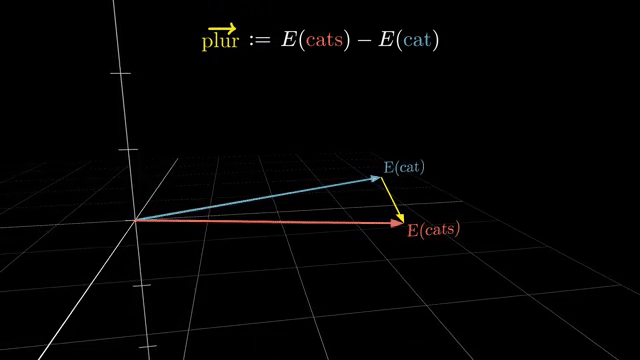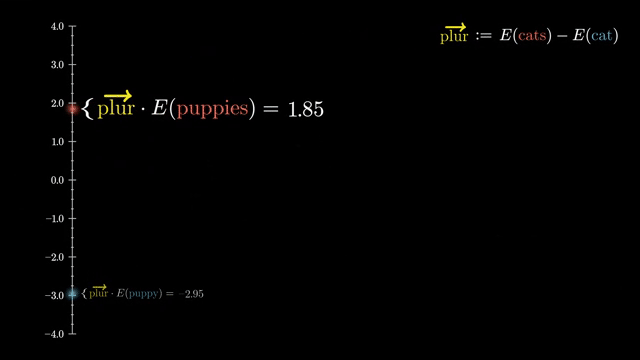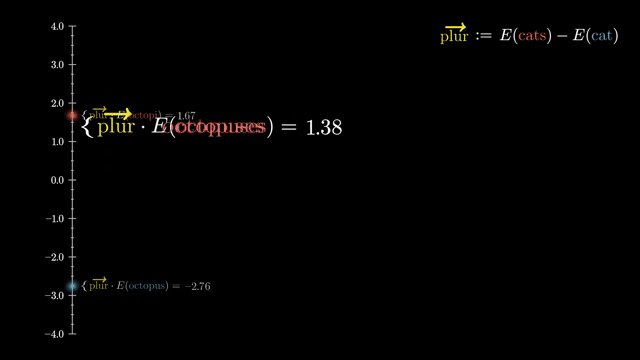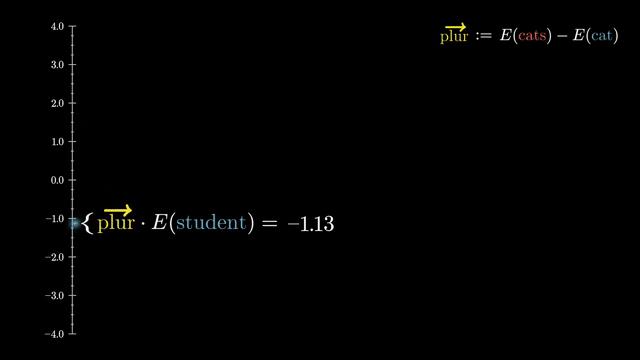
Learning rate warmup gradually increases $\eta$ early in training. Large adaptive steps on cold random weights can destabilize attention logits and optimizer moment estimates; warmup lets scale settle before full-speed optimization .
Weight decay shrinks weights toward zero each step, improving generalization in many LLM runs when paired with AdamW. Gradient clipping uses a global norm cap so one bad batch cannot dominate the update .

restart from a checkpoint. Monitoring validation loss, gradient norms, and activation statistics is routine at scale .
Checkpointing every few thousand steps is cheap insurance: loss spikes sometimes recover under cosine decay, but a diverged run without a checkpoint wastes days of GPU time .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
