Encoder vs decoder masking
Not every transformer attends the same way. Encoder blocks (BERT-style) use bidirectional attention: every token may attend to every other token in the input. That suits masked language modeling, predicting held-out tokens from full context .
Decoder blocks in autoregressive models (GPT-style) apply a causal (triangular) mask: position $i$ may attend only to positions $j \le i$. Future tokens are invisible during training, preserving the left-to-right generation order .

Encoder-decoder architectures (T5, original translation transformers) stack an encoder over the source and a decoder that cross-attends into encoder outputs while still using causal self-attention internally .
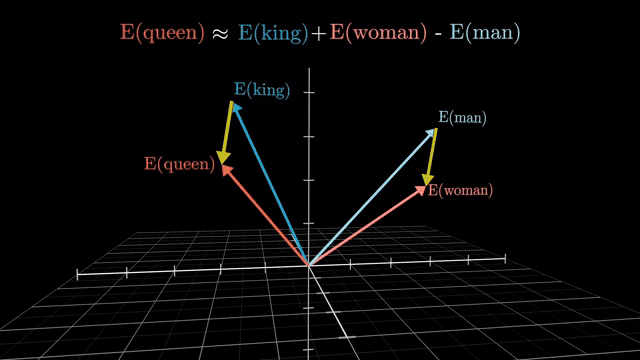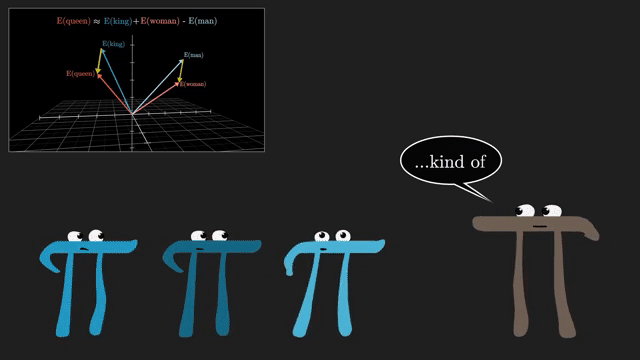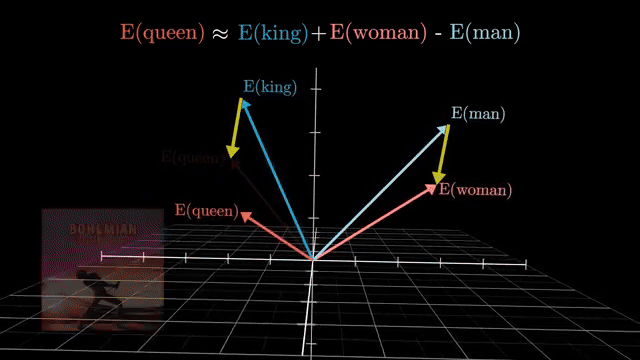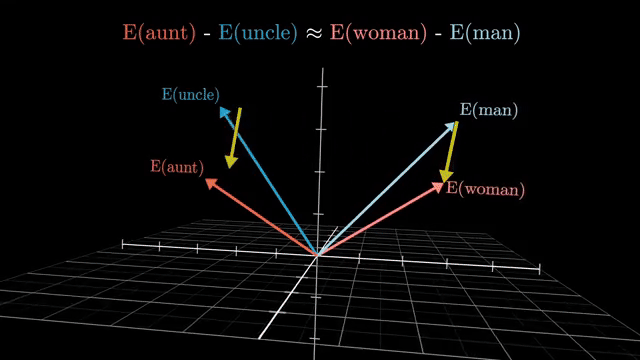
Mixing these regimes breaks objectives. If a causal mask is disabled during GPT training, future tokens leak into predictions, inflating metrics and destroying valid autoregressive generation. If you need bidirectional context, you must train with a bidirectional objective and inference protocol to match .
Unit tests for attention masks should assert forbidden positions receive zero probability mass after softmax, not merely large negative logits that could underflow inconsistently across hardware .
Production code often factors mask construction into a reusable helper shared by training and inference so eval mode cannot accidentally drop causality .
Document which mask tensor is applied in eval versus train; many production bugs come from forgetting to rebuild the causal mask when exporting to ONNX or TensorRT .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
