Transformer block: attention + MLP + residuals + norm
A transformer block stacks two sublayers around a residual highway. First, multi-head self-attention mixes tokens; second, a positionwise feed-forward network (FFN) applies the same MLP independently at each position .
The FFN is typically two linear maps with a nonlinearity in between, often expanding to $4\times$ model width before projecting back:
$$\mathrm{FFN}(x) = W_2\,\sigma(W_1 x + b_1) + b_2.$$
Attention handles who talks to whom; the FFN handles per-token nonlinear transformation after mixing .
Residual connections add sublayer inputs to outputs: $x + \mathrm{Attention}(x)$ and $x + \mathrm{FFN}(x)$. They provide gradient shortcuts through depth, mitigating vanishing signal in very deep stacks . LayerNorm or RMSNorm standardizes activations per token before each sublayer; pre-norm (norm first, then sublayer) often trains more stably than post-norm in large models .
Modern LLM FFNs often use SwiGLU gating: one linear branch is multiplied by a swish-activated gate branch before the down-projection. That adds parameters but improves quality per FLOP in many pretraining runs .
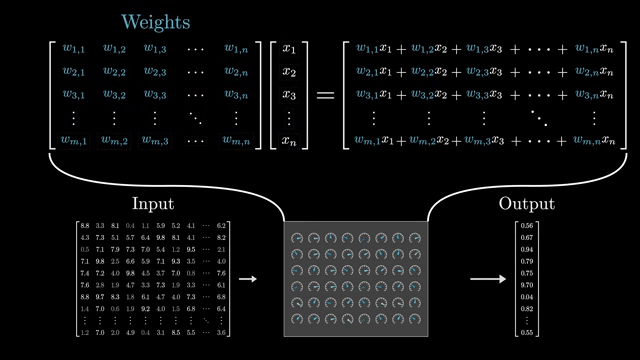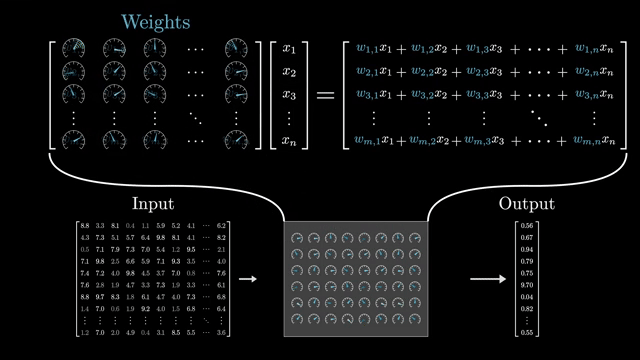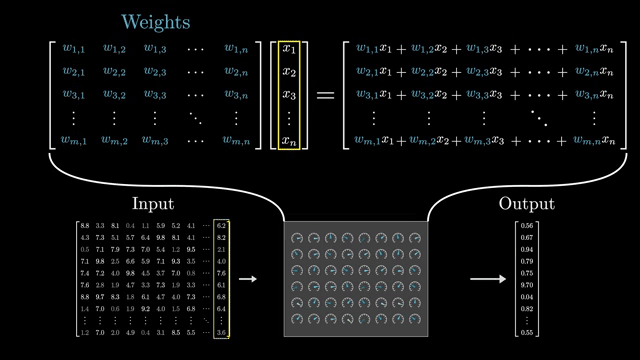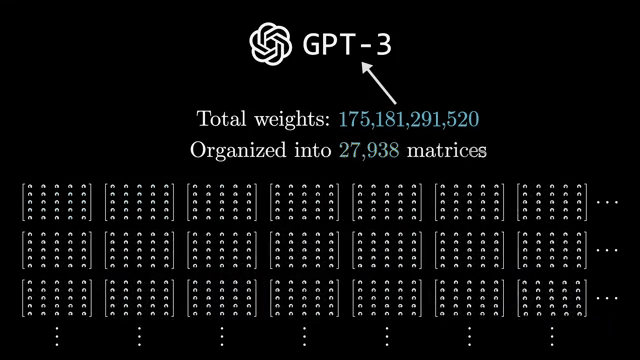
Stacking $L$ identical blocks (with distinct weights) yields depth $L$. Each block refines representations while residuals preserve a path for raw information to propagate forward . Pre-norm stacks often tolerate larger learning rates because gradients flow through norm-scaled sublayers before the residual add .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
