Bridge to transformer mechanisms
Language models before transformers often used RNNs: a hidden state updated serially along time, creating a bottleneck for very long contexts . Transformers replace much of that recurrence with self-attention, mixing tokens in parallel within each layer plus positional structure .
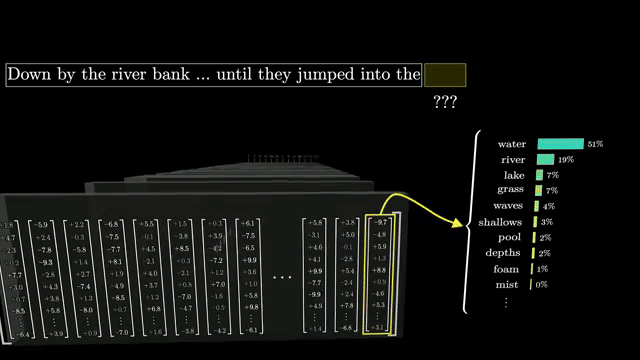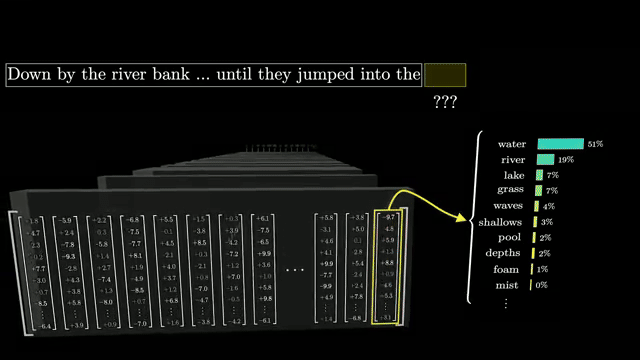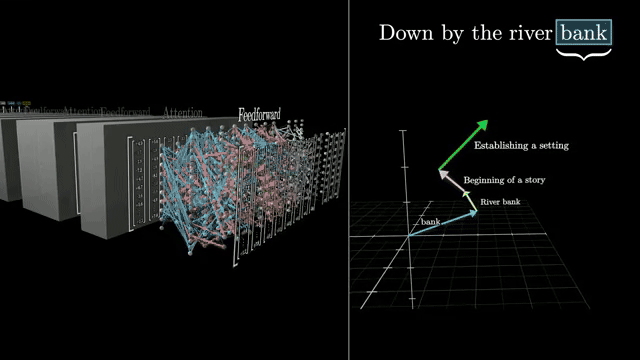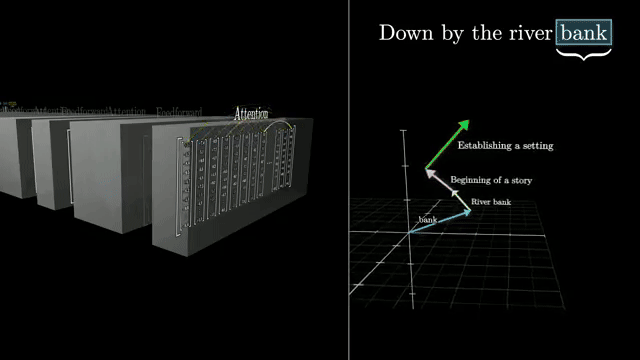
Naive full self-attention compares every token to every other token in a layer, giving $O(n^2)$ time and memory in sequence length $n$. That cost motivates sparse, linear, and state-space approximations in research models .

Hybrid stacks combine attention with convolutions, recurrence, or state-space blocks selectively. Later chapters in the playlist mechanize query-key-value maps, masks, and transformer blocks that make the autoregressive loop practical at scale .
Understanding the LLM story at a high level sets up why attention, not deeper RNN unrolling, became the default long-range mixer .
Chapter 6 opens the transformer block: query-key-value attention, positional encodings, residual streams, and the engineering tricks that make billion-parameter training stable .
Attention will reappear as the central mechanism for mixing token information; the LLM overview you just finished supplies motivation for why that mechanism replaced recurrence at scale .
Quadratic attention cost is why serving long contexts is expensive: memory for keys and values grows with sequence length even when compute is optimized with caching .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
