Scale: data, compute, and emergent capability patterns
Empirically, validation loss often improves predictably as model size, data, and compute grow. Log-log plots of loss versus parameters or FLOPs show scaling-law slopes that guide budgeting, though they are empirical fits, not physical constants .

Some downstream abilities appear sharply once scale crosses thresholds: in-context learning from prompts, rudimentary tool use, or chain-of-thought style reasoning. These emergent patterns are not hand-coded rule engines; they arise from optimization on next-token loss .
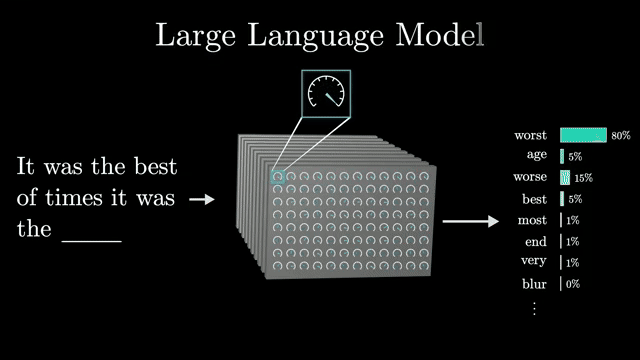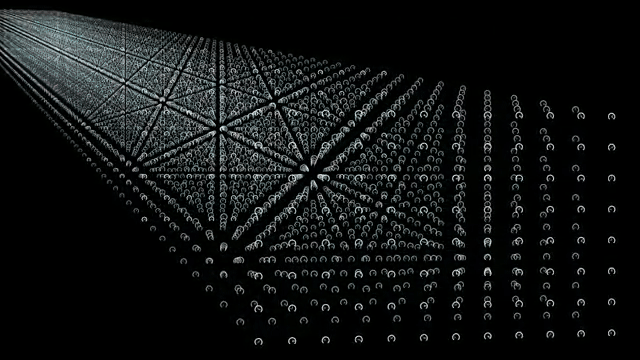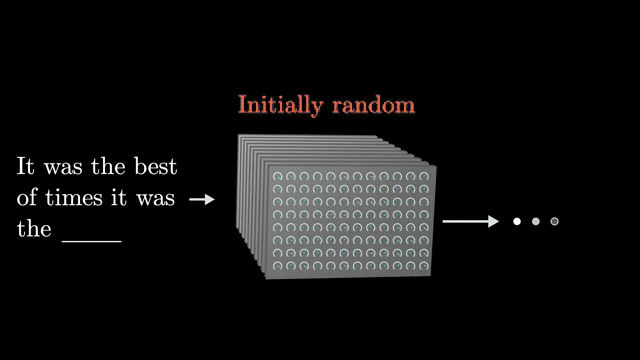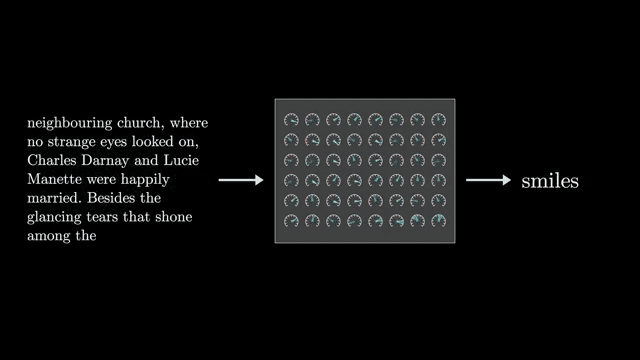
Chinchilla-style analyses argue that, under fixed compute, you should balance model width and training token count rather than widening alone. Data quality and contamination in evaluations complicate extrapolation from small models to future frontier systems .
Scaling trends help planning but do not guarantee qualitative capability jumps or unbiased benchmarks at every scale .
Loss curves alone do not tell you whether a model can follow instructions, refuse harmful prompts, or reason reliably; those behaviors depend on data mix, scale, and post-training stages discussed later in this module .
Compute-optimal training is not only about FLOPs: data filtering, deduplication, and mixture design change which capabilities appear even when parameter counts are held fixed .
Emergence is debated terminology: some researchers argue apparent jumps are metric artifacts, others emphasize genuine qualitative change. Either way, small-model curves are weak predictors of frontier behavior .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
