Autoregressive core loop: predict the next token
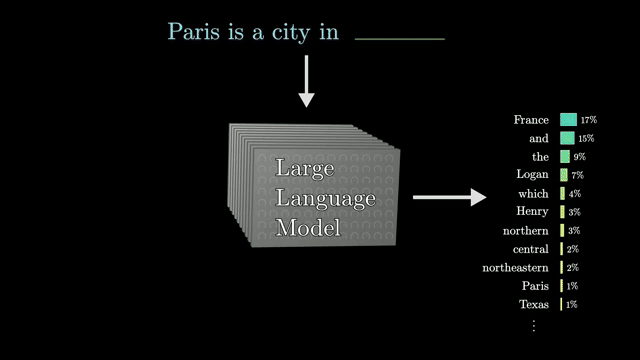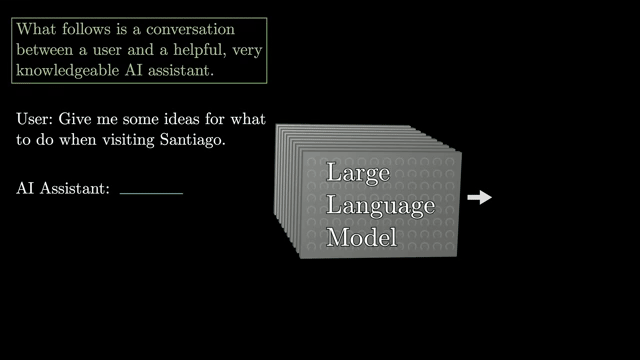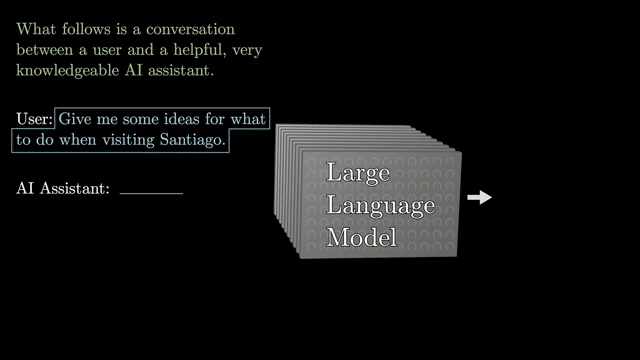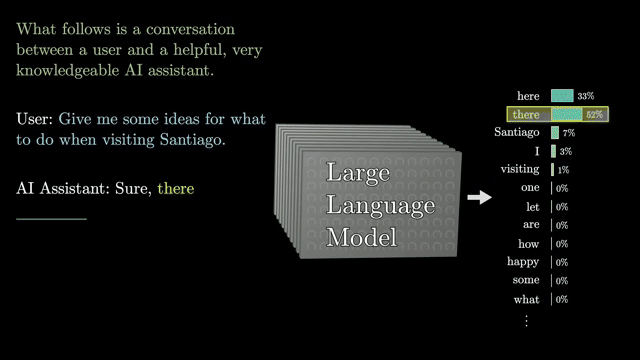
Large language models treat text as a sequence of discrete tokens (subwords or bytes). At each position the model outputs a distribution over the vocabulary; training pushes probability mass onto the next token observed in the corpus, typically via cross-entropy on logits .
Generation repeats the loop: sample or argmax a token, append it to the context, run another forward pass. That autoregressive structure is the same idea as character-level models, only the vocabulary and depth grew .

A tokenizer maps Unicode text to token IDs; detokenization maps back for display. Context length limits how many prior tokens can influence the current position through attention or recurrence .
At inference, temperature rescales logits before softmax: low temperature sharpens the distribution (more deterministic), high temperature flattens it (more random). Top-$p$ (nucleus) sampling truncates the smallest tail of the distribution while keeping most probability mass .
Pre-training therefore optimizes next-token predictive accuracy over massive text, not explicit human preference labels .
Each forward pass produces a vector of logits with length equal to vocabulary size, often tens of thousands of entries. The model reads context left to right during causal pretraining, so position $t$ never sees tokens after $t$ .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
