Transition to scaled autoregressive modeling
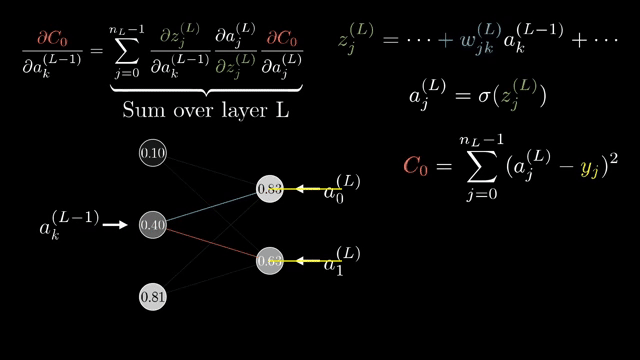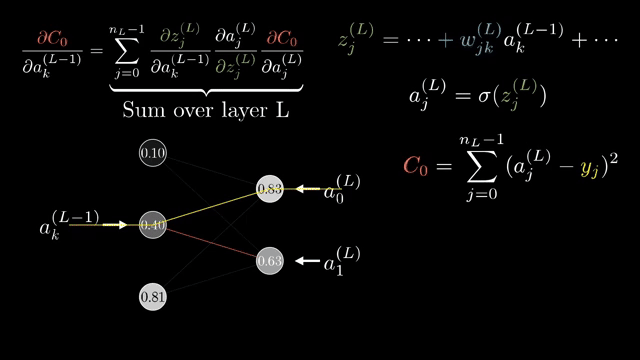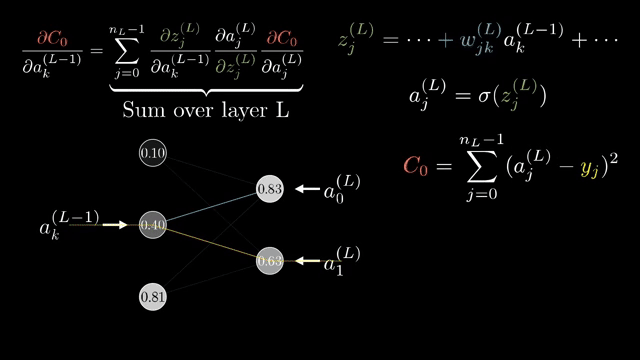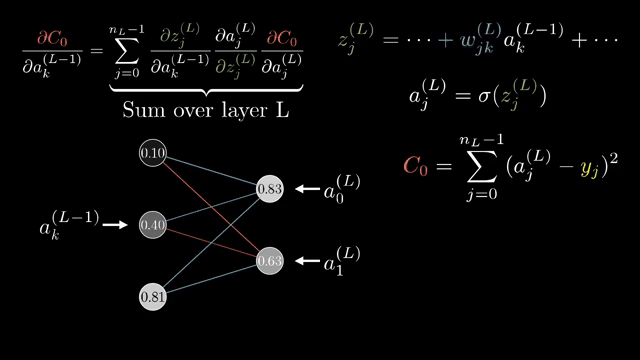
The calculus hygiene on small graphs parallels the massive tensor programs inside language models: same chain rule, vastly wider tensors. Static-graph frameworks record and optimize the graph ahead of time; eager frameworks build it operation by operation. Both rely on registered VJPs .
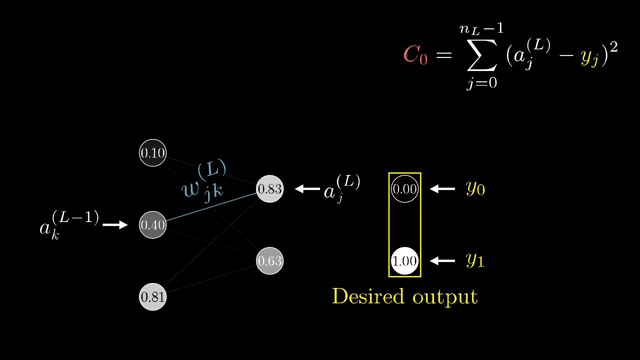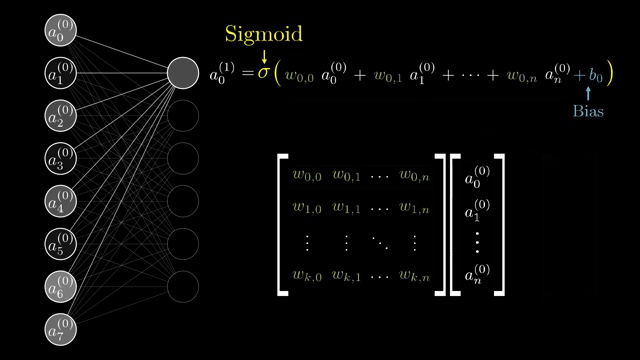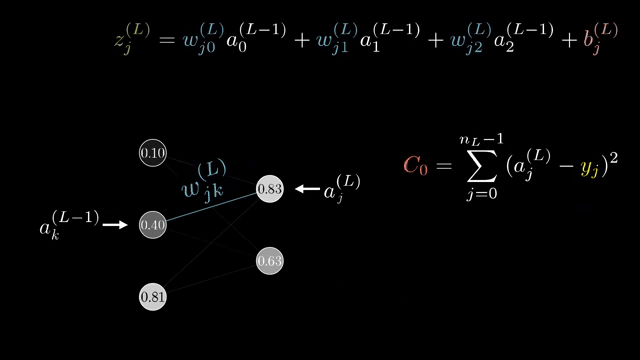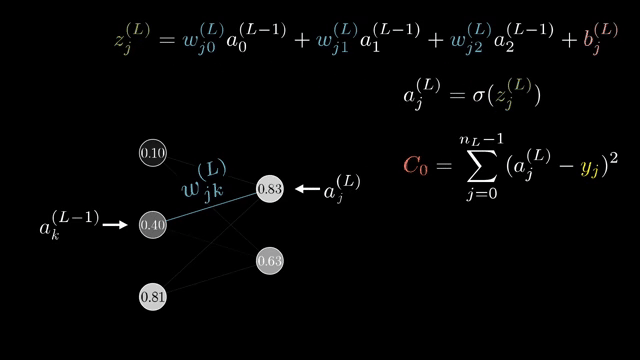
Finite-difference checks remain valuable on toy models even when production training never uses them at scale. They catch sign errors that slip past shape checks .
Advanced theory (neural tangent kernels, infinite-width limits) studies gradient descent dynamics in simplified regimes; it is not required to deploy models but informs research .
Chapters 5 through 8 pivot from handwritten partials toward autoregressive language modeling, transformers, and mechanistic questions about how facts live in weights .
The calculus exercises you completed on small graphs are the same logical moves executed billions of times per second inside tensor cores when a language model trains, only with taller matrices and fused kernels hiding the node labels .
You are now leaving the 2017 calculus-centric trilogy and entering modules where scale, data governance, and architecture choices dominate the conversation as much as partial derivatives .
The playlist now treats language as data: token sequences, massive corpora, and deployment constraints that the MNIST chapters only hinted at through parameter counts .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
