Handoff to the calculus-heavy walkthrough
This chapter kept the graph picture intuitive. The next chapter slows down and writes partial derivatives with explicit subscripts on small lattices of variables, the algebra that scales when you implement layers by hand or read research appendices .
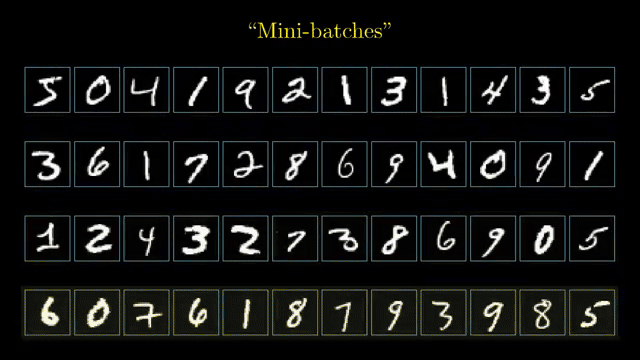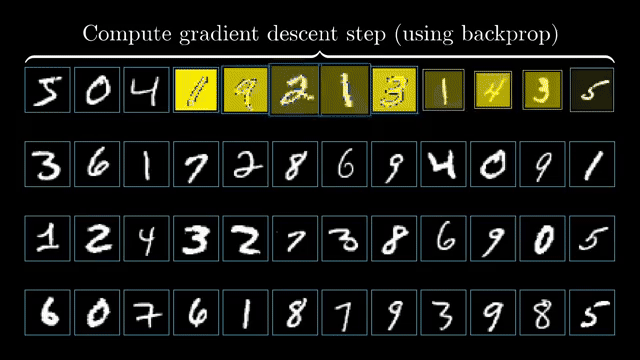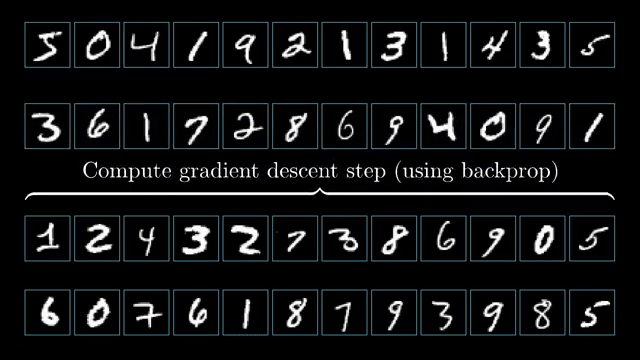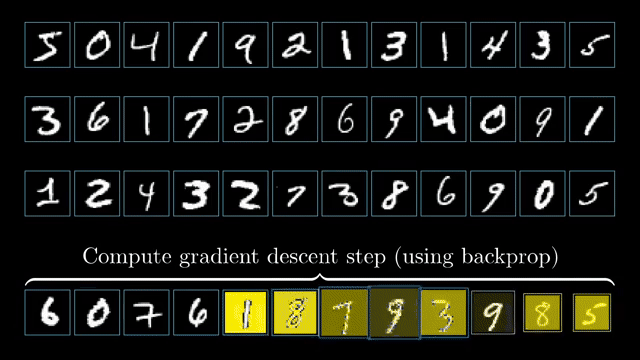
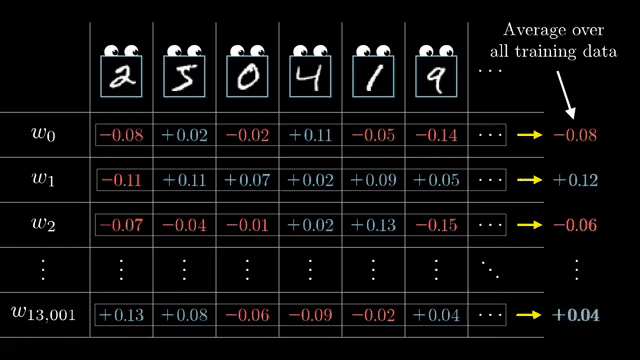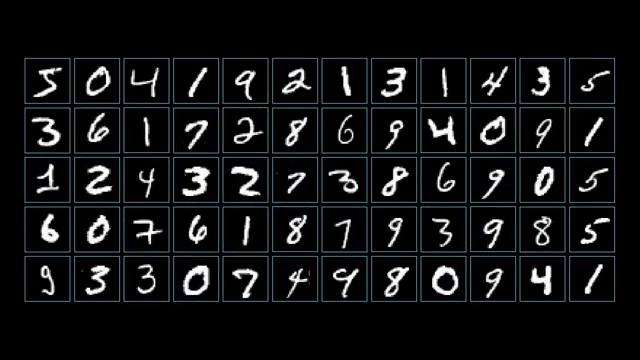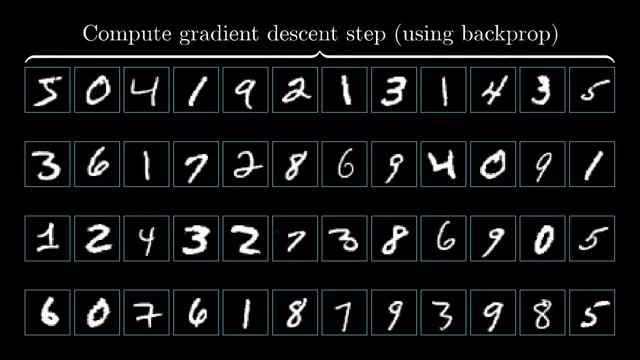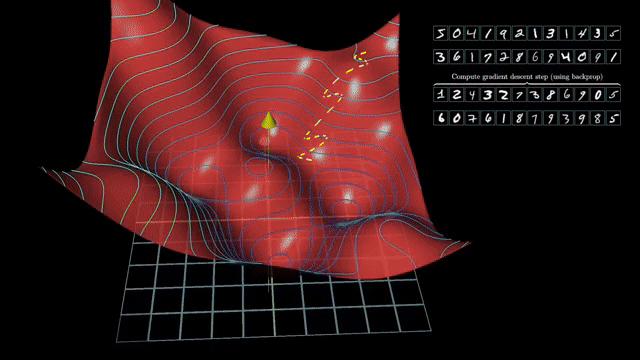
Matrix calculus conventions (numerator vs denominator layout) determine whether gradients are row vectors or column vectors and whether Jacobians need transposes. Silent layout mistakes are a top source of shape bugs in manual derivations .
Long chains multiply many Jacobians; ill-conditioned products amplify numerical error. Mixed-precision training stores activations in low bit width but must scale loss and accumulate sensitive sums carefully to preserve tiny gradients .
Symbolic differentiation without sharing can duplicate subexpressions explosively; AD on graphs avoids that blow-up. The upcoming chapter spells out fan-out summations and subscripts on concrete examples before the playlist pivots toward language models .
Treat the intuitive graph picture from this chapter as the map and the next chapter as the turn-by-turn directions: same terrain, finer notation .
Keep the DAG mental model when you watch the calculus chapter: every partial written on paper is one edge label in the larger graph you already understand .
If any step felt abstract, revisit the small graph animations with the chain rule in mind: each backward arrow is a local partial multiplied into the running sensitivity .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Intermediate
- Completed: 0 users
Creator
