Bridge to automatic differentiation next
Gradient descent is useless without efficient partial derivatives. A naive finite-difference estimate perturbs one weight at a time: for $N$ parameters you need on the order of $N$ forward passes per gradient, which is prohibitive when $N$ is in the millions .
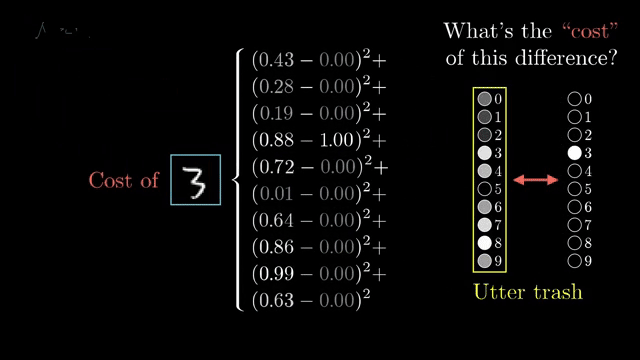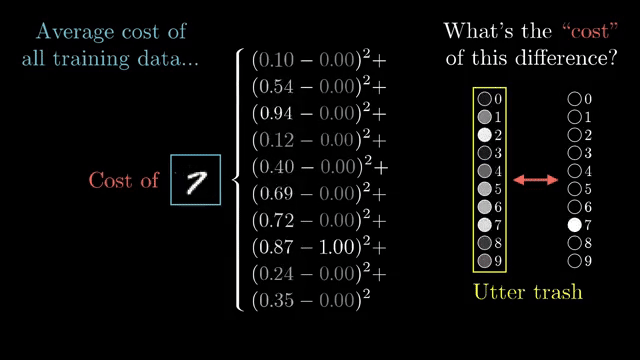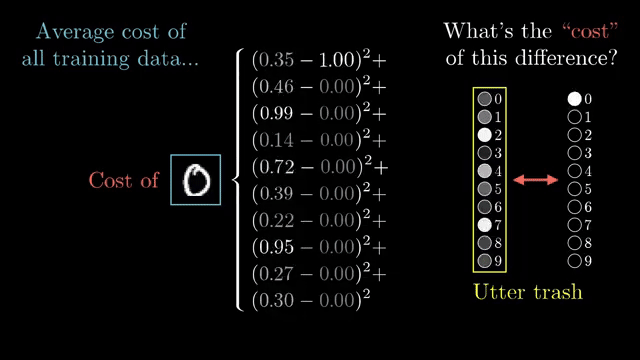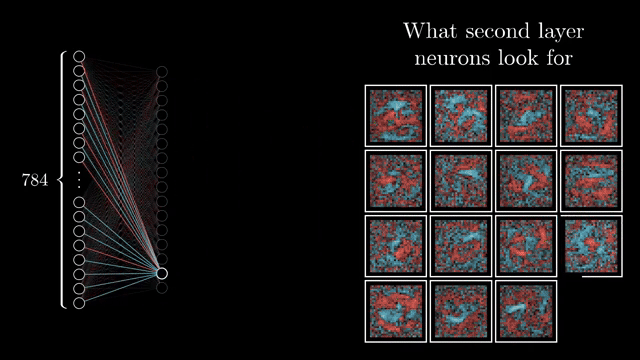
Backpropagation is reverse-mode automatic differentiation on the network's computation graph. Because the final cost is a single scalar depending on all parameters, reverse mode computes every $\partial C/\partial w_i$ in roughly one forward pass plus one backward pass, reusing shared subexpressions via the chain rule .
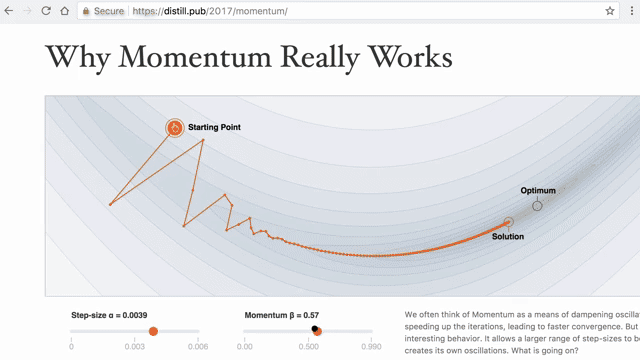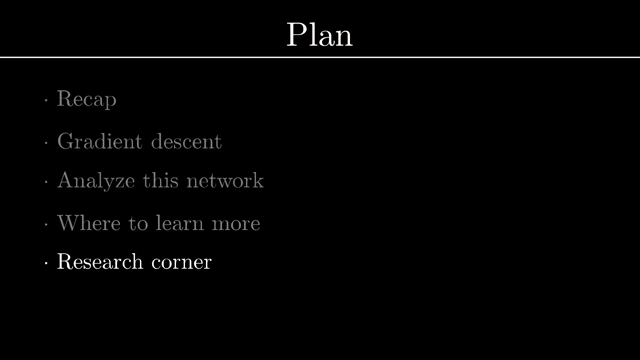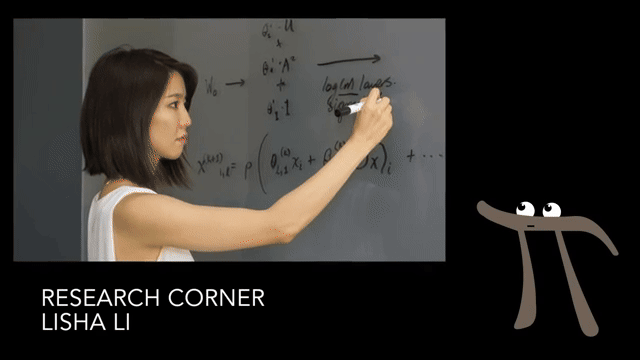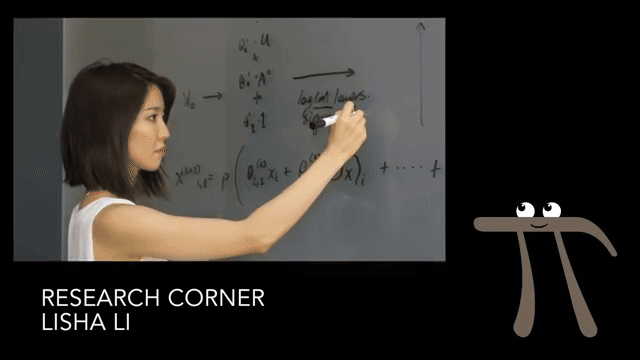
Forward-mode AD, by contrast, tracks one input's influence through all outputs; it is better when few inputs affect many outputs. Neural training is the opposite pattern: one loss, many weights .
Gradient clipping caps exploding gradient norms before the optimizer step, a stability trick especially common in recurrent and very deep models. The next chapter in the series opens the computation graph and walks the chain rule edge by edge .
Once backprop is available, the same descent loop from this chapter drives every deep learning system: forward pass, loss, backward pass, optimizer step, repeat until validation metrics satisfy your budget .
The chapter closes by pointing at automatic differentiation: the mechanical engine that makes gradient descent practical on networks with thousands of weights, not a separate learning algorithm but the derivative bookkeeping behind the scenes .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Beginner
- Completed: 0 users
Creator
