Momentum and adaptive methods (conceptual)
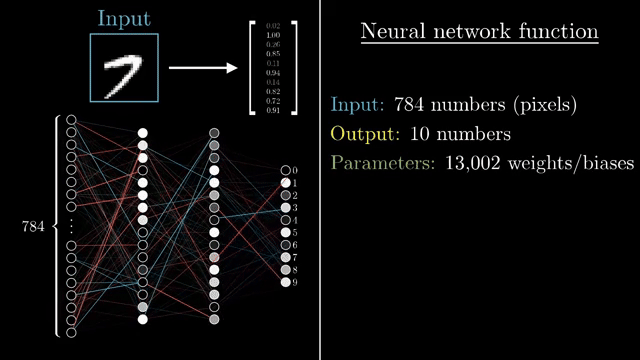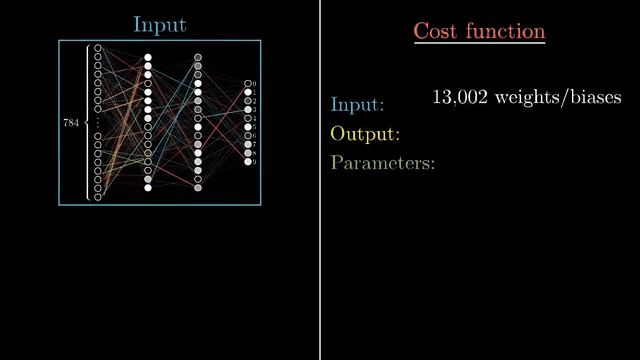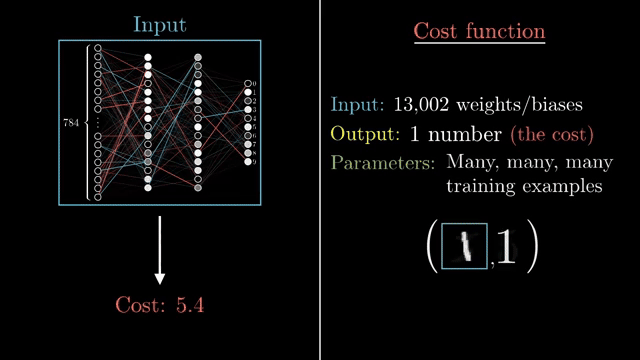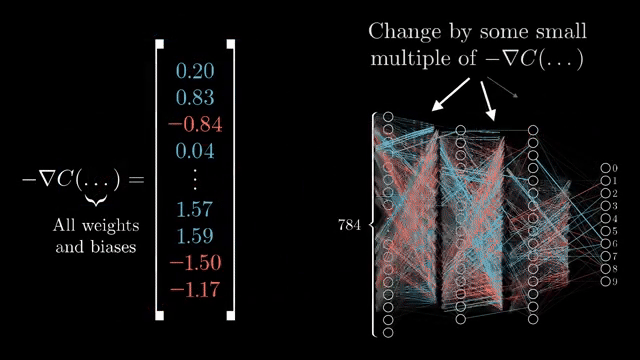
Plain SGD uses only the current batch gradient. Momentum maintains a velocity vector $\mathbf{v}$ that accumulates past gradients with exponential decay, then updates weights along $\mathbf{v}$ rather than along the raw gradient alone . Along narrow ravines, oscillating components cancel while consistent downhill components reinforce, much like a ball gaining speed down a valley.
Adaptive methods rescale steps per parameter. AdaGrad divides by growing sums of squared past gradients, shrinking steps for frequently updated coordinates. Adam combines momentum on first moments with variance estimates on second moments, giving each weight its own effective learning rate .
These optimizers are workhorses in practice, yet they introduce new hyperparameters (decay rates, epsilon stabilizers, weight-decay coupling). The exposition foregrounds intuition; production training stacks add gradient clipping, warmup, and schedule tweaks on top .
Tracking moving averages of gradients therefore serves two roles: damp oscillation across ravine walls and accelerate motion along directions where the signal is consistent across iterations .
Nesterov momentum looks ahead along the velocity direction before evaluating the gradient, often improving convergence on convex-like valleys. RMSProp and AdamW variants appear in modern vision and language stacks, but the intuition here remains: smooth noisy directions and adapt step sizes .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Beginner
- Completed: 0 users
Creator
