The cost function as a high-dimensional surface
Chapter 1 showed how a forward pass turns pixels into digit guesses; this chapter asks how those thousands of weights get chosen. Training defines a cost function $C$ that measures average mismatch between predictions and labels. For classification, that is typically cross-entropy over softmax outputs; the exact formula matters less here than the picture: every parameter setting $\mathbf{w}$ assigns a height $C(\mathbf{w})$ .
Imagine only two weights so you can draw a surface. Valleys correspond to lower error; ridges and bumps correspond to worse fits. Real networks have millions of coordinates, so the true landscape lives in a space you cannot plot, but the metaphor still guides algorithm design: we want to roll downhill .

The gradient $\nabla_{\mathbf{w}} C$ collects partial derivatives $\partial C/\partial w_i$. It points in the direction of steepest increase of the cost at the current point. Gradient descent steps opposite that vector:
$$\mathbf{w} \leftarrow \mathbf{w} - \eta \nabla_{\mathbf{w}} C,$$
with step size $\eta\gt 0$ called the learning rate .
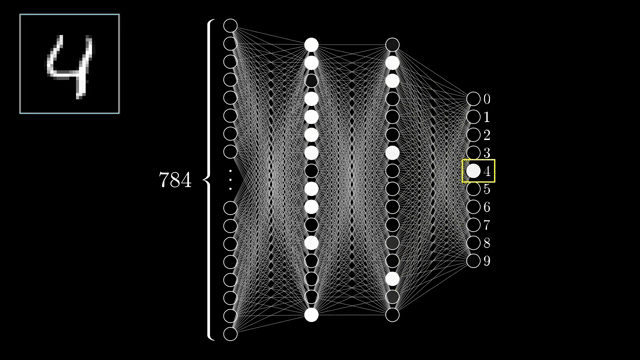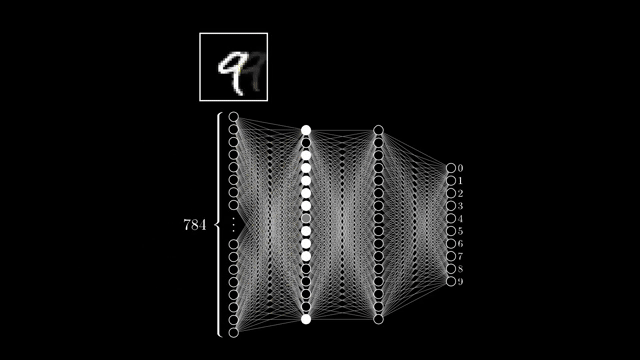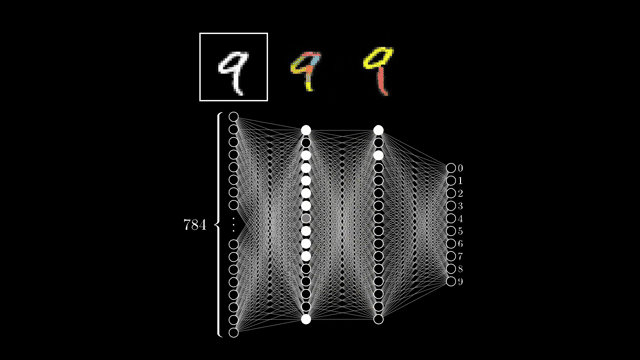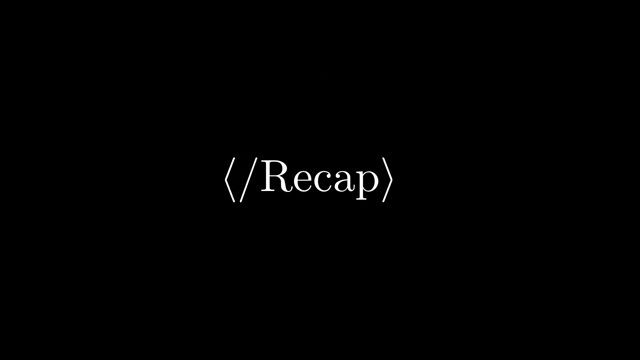
A critical point satisfies $\nabla C = \mathbf{0}$ in smooth unconstrained settings. That includes minima, maxima, and saddles; descent only guarantees local improvement, not a global optimum. The two-weight slice shown is a pedagogical cartoon, not a faithful projection of MNIST weight space .
Related cards
Video Content
Tasks
Card Info
- Topic: Machine learning
- Difficulty: Beginner
- Completed: 0 users
Creator
