Preview: duality links rows to linear functionals
Rows act on column inputs even before the dedicated dot-product chapter: each row defines a linear functional on $\mathbb{R}^n$ . Nonsquare height changes how many independent functionals you stack at once.
Transpose swaps $m$ and $n$, reversing the map direction symbolically. Row rank equals column rank; for real matrices, $\mathrm{rank}(A^T A)=\mathrm{rank}(A)$.
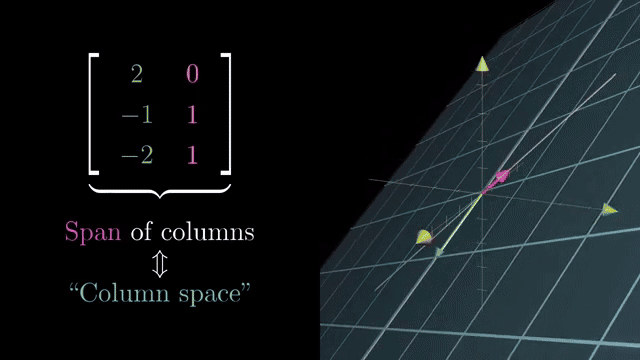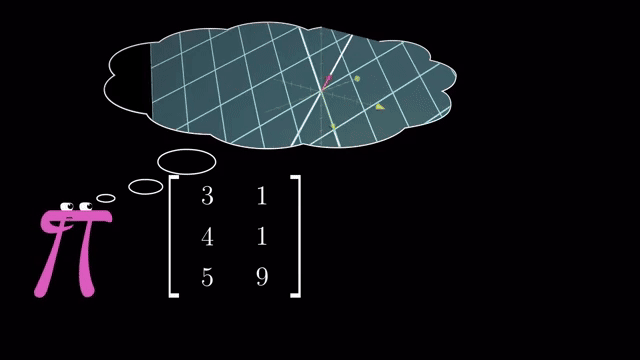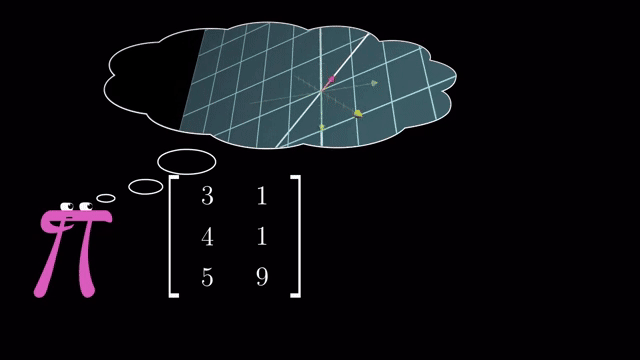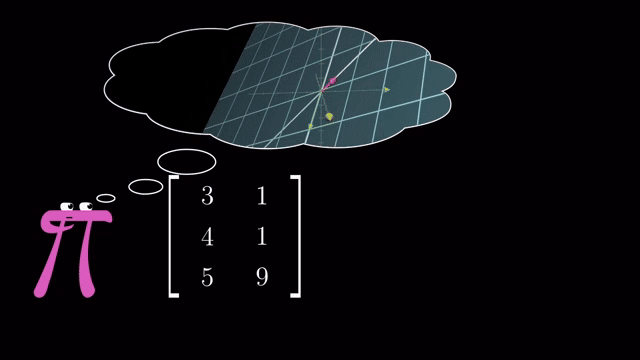
When $\mathbf$ weights outputs, $A^T\mathbf$ combines rows of $A$ back into the domain side. That is the dual-side picture of pairing outputs with inputs. For real matrices, $\mathrm{rank}(A^T A)=\mathrm{rank}(A)$, so Gram matrices do not hide rank .
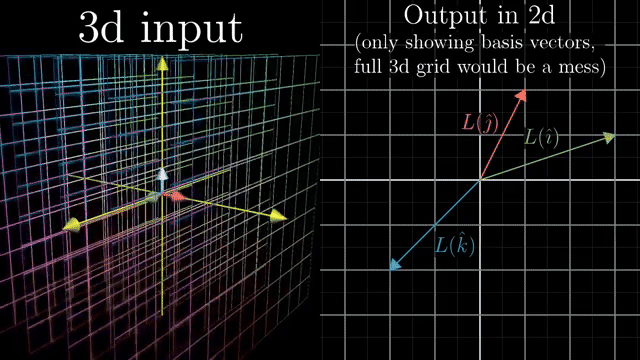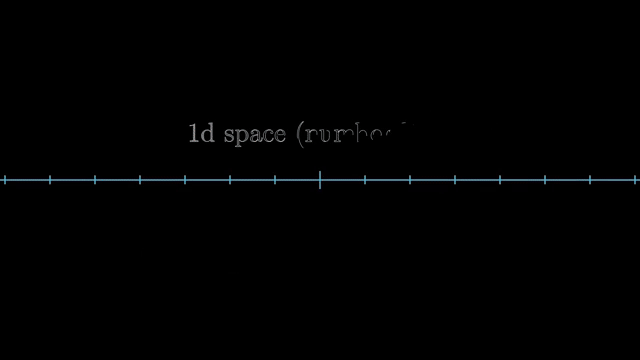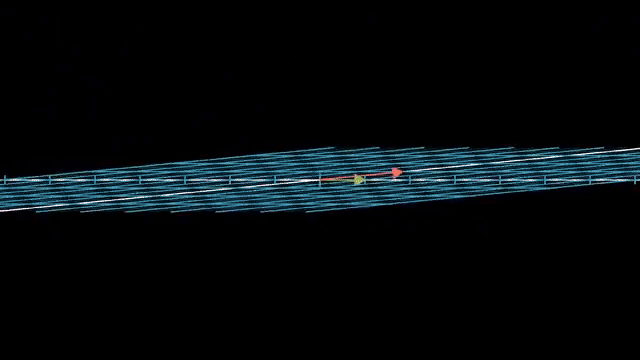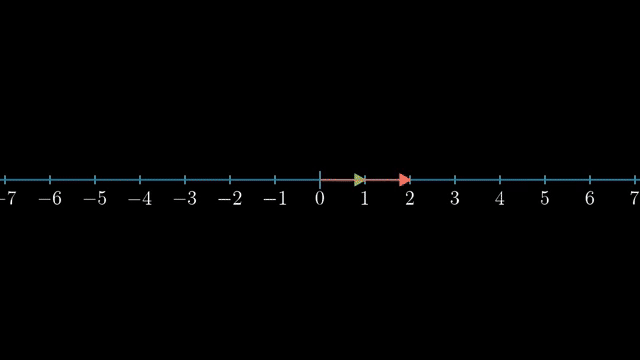
Keep shapes straight: $A:\mathbb{R}^n\to\mathbb{R}^m$ while $A^T:\mathbb{R}^m\to\mathbb{R}^n$. Row rank equals column rank, so counting independent rows and independent columns gives the same number even when the matrix is not square. Transpose reverses the map direction while swapping $m$ and $n$ in the shape . Rows act as linear functionals on inputs before the dot-product chapter makes that geometric. $A^T\mathbf$ weights rows and lands back in the domain side. Row rank equals column rank for every matrix shape.
Related cards
Video Content
Tasks
Card Info
- Topic: Mathematics
- Difficulty: Intermediate
- Completed: 0 users
Creator
