Wide matrices: fat unknowns, short equations
When $m\lt n$, you have more unknowns than scalar equations. Either many free variables remain or constraints eliminate some. Full row rank $m$ means every $\mathbf{b}\in\mathbb{R}^m$ is reachable: the map is surjective onto its codomain .
If a wide system is consistent, the solution set is an affine space of dimension $n-m$: add any kernel vector to a particular solution. Data-science design matrices are often wide; regularization chooses among many near-solutions.
Wide matrices with $m\lt n$ always have nontrivial nullspace in generic rank situations: at least one direction collapses to zero output. That is the pigeonhole principle for linear maps.
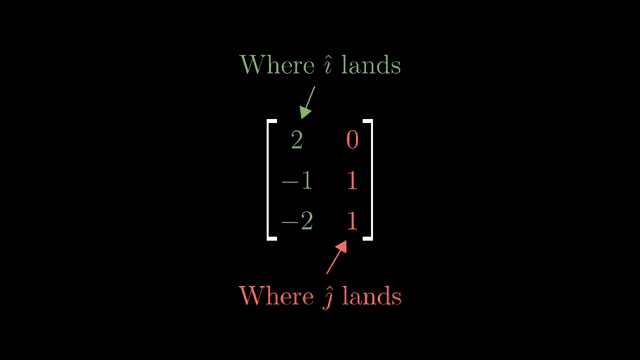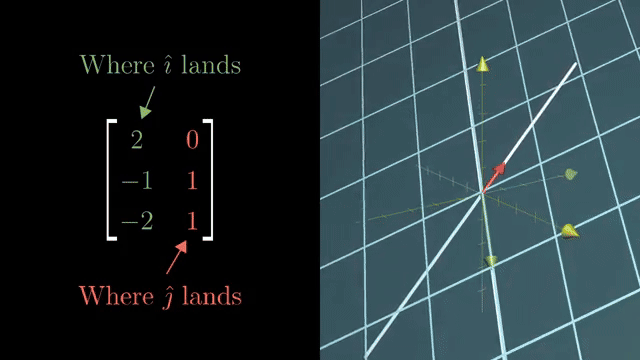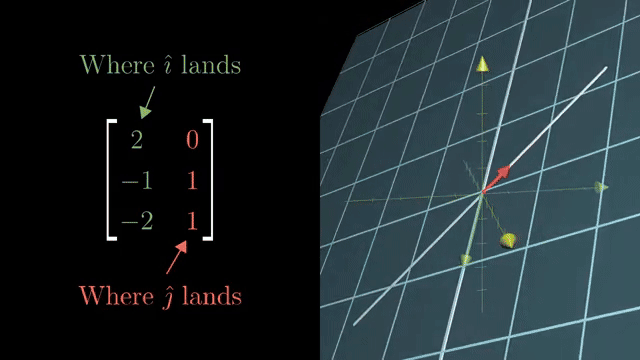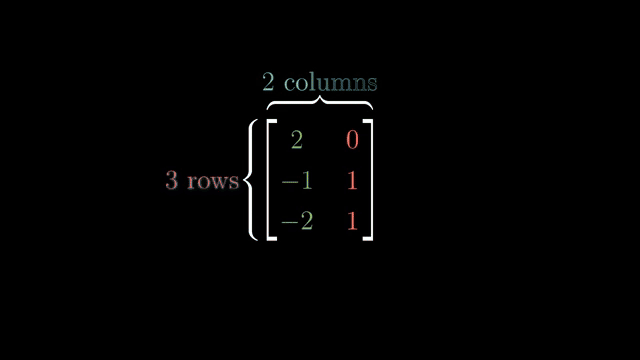
Example domains: genomics panels with vastly more features than samples, or imaging problems with many more pixels than measurement rows. Regularization (ridge, lasso) picks among many near-solutions when the null space is large; that is the practical response to underdetermined wide systems. Consistent wide systems have solution affine spaces of dimension $n-m$ . Full row rank $m$ means every $\mathbf{b}\in\mathbb{R}^m$ is reachable. Nontrivial nullspace is guaranteed for wide $m\times n$ with $m\lt n$ in typical rank cases. Genomics panels are a real wide-matrix example.
Related cards
Video Content
Tasks
Card Info
- Topic: Mathematics
- Difficulty: Intermediate
- Completed: 0 users
Creator
